关系代数+SQL代码:50分
E-R图 :20分
函数依赖:10分
学习通7~10章琐碎知识:20分,选择题
其他部分不做考核要求
引言
这一部分是数据库的一些基本概念
Data:数据
Data Base:数据库
Data Base Management System(DBS):数据库管理系统
1.2 数据库系统的目标
传统的程序数据管理使用文件系统系统,使用文件来储存信息。但是有很多弊端,如:数据冗余和不一致、数据访问困难、数据孤立、完整性问题(数据的值是否正确反应了现实,比喻表示金钱的数据不能为负数)、原子性问题(银行汇款,扣款和收款的数据必须都进行或都不进行,不能进行一步,然后卡死)、并发访问异常、安全性问题(即数据的访问权限问题)。
1.3 数据视图
数据库系统的结构中有三个抽象的层次,来屏蔽复杂性:
- 物理层:实际的数据是怎样储存的,描述最底层的数据接口(如STL map的物理层是红黑树),是数据库的开发人员使用的层次。
- 逻辑层:描述数据库中的数据之间的关系,是数据库的管理人员使用的层次,描述整个数据库。
- 视图层:最高的层次,只描述数据库的某个部分,为用户直接看到的信息。对于不通权限和需求的用户,可以提供不通的视图层。
在数据库中,逻辑层不必知道物理层的复杂实现,被称为物理数据独立性。视图层用户不必知道后台的数据逻辑,称为逻辑数据独立性。
在数据库中,数据库某个时刻的所有信息的集合称为数据库的一个实例。
数据库的总体设计被称为模式。而根据之前的抽象层次,也分为物理模式、逻辑模式。由于视图层有好几个模式,被称为子模式。 其大体逻辑为:
1. 数据库=数据库语言+模式;
2. 模式=数据结构+完整性约束+数据操作(数据模型的三要素)
数据库的结构基础是不同的数据模型。一共有四类数据模型。除实体-联系模型外,全部都是逻辑模型。
- 关系模型。
- 实体-联系模型:唯一的概念模型,是一种设计理念。
- 基于对象的数据模型。
- 半结构化数据模型:如HTML就是典型的半结构模型。
关系型数据库
2.1 关系型数据库的结构
关系型数据库有表的集合组成,每个表有唯一的名字。
表中的一行代表一组值之间的联系(类似笛卡尔乘积的一个子集)。在术语中,关系代表表、元组代表行、属性代表列,用关系实例来代表一个关系的特定实例,即一组特定的行。
关系是元组的集合,而元组在关系中出现的顺序是无关紧要的。
对于每个属性,都有取值范围的几个、,称为域。如果域中的元素不可再分,则称该域是原子的。比如某个属性为“身份证号”。如果我们把它差分为“出生信息”、“地域信息”……那么我们实际上是把它作为非原子域对待的。
在剩余部分,如果不特殊强调,默认域是原子的。
2.3 码
超码:一个或多个属性的集合,可以唯一的标识一个元组。超码不唯一,超码的任意超集都是超码。
候选码:超码中可能后很多不必要的属性。我们把最小的那个称为候选码,即它的任意真子集不是超码。候选码的个数也不唯一。
主码:当我们选定某一个候选码来作为区分元组的标识,这个码就变成了主码。
外码:如果关系R1中有一个属性是关系R2的主码,那么这个属性在R1中被称为R2的外码。
外码的作用是参照完整性约束的。比如在R1中添加新元素时,如果该属性作为了R2的外码,则必须保证R2存在这个新的值,否则就不允许添加 。
SQL
很自然的重点章节了
SQL语言分为DDL(definition)定义数据库结构、DML(manipulation)对数据进行操作、DCL(control)管理数据库权限三类。
DDL 数据定义语言
-- 创建表
create table tablename(
name type, -- 表项
...
contraint -- 约束(可选)
);
-- 删除表
drop table from database;
-- 更改表
alter table tablename add nameA type;
alter table tablename drop nameB;
完整性约束
完整性约束是用来限制表的增删改操作的。只有DDL语句可以更改完整性约束。SQL中实现的完整性约束主要有:
实体完整性:外键、主键
用户定义完整性:unique、not null、check(condition)
- 主键可以在定义数据时直接放到后面,也可以在末尾添加。放在列后面时只能包含一项。
- 外键、unique、not null约束的定义与主码类似,只包含一项时何以放到数据定义后面,多项必须放到末尾。
- check(condition)只能放到末尾,内部为约束条件。
除了在创建表的时候规定完整性约束外,在表定义好之后,也可以通过alter语句来增加/修改/删除任意完整性约束。
一个外键约束最多只能关联2个表(可以只关联一个表,即自关联)。
DML 数据操控语言
SQL语句不区分大小写,语法顺序固定。
insert
-- 插入语句
insert into tablename values() -- values中填写与表定义的所有属性值
insert into tablename(P1, P3, P5) values(V1, V3, V5) -- 填写部分属性
填写部分属性的insert处理有两种:
- 直接赋null,在忽略的属性中有not null约束时出错。
- 定义表的时候定义默认值。
update
-- 更新
update tablename
set value_change-- 填写更改
where contidion -- 更改的条件。没有条件更改所有元组
delete
-- 删除,按行操作
delete from tablename
where contition
select
强调:select语句也是DML的一部分。
查询语句
不涉及语法部分,只强调易错、重点内容
查询语句的执行顺序
- from 子句组装来自不同数据源的数据;
- where 子句基于指定的条件对记录行进行筛选
- group by 子句将数据划分为多个分组
- 使用聚集函数进行计算
- 使用having 子句筛选分组
- 计算所有的表达式
- select 的字段
- 使用order by 对结果集进行排序
查询语句的重点强调
- order by默认为升序(
asc),添加desc实现降序 - join on 语句注意主键为多个属性的表的连接条件
- join type: inner join(默认), left outer join, right outer join, full outer join(省略使用outer)
- null的处理:
- null进行算数运算结果仍然时null
- null进行逻辑运算,
null or true = true,null or false = null,false and null = false,true and null = null,not null = null - 除count(*)意外所有的聚集函数都忽略输入中的null
- 三个集合运算名词:union、intersect、except
- 参与集合运算的两个子查询,必须满足属性数量和属性类型兼容(不需要相同那么严格)
子查询
SQL查询的结果是一个表。因此可以再次用来做子查询。
子查询分为两类(从使用方式上):不相关和相关子查询。
-- 不相关子查询,子查询可以独立运行
select * from emp where deptnp in (select deptno from dept where loc='CHICAGO')
-- 相关子查询,依赖外层数据
select * from emp where exists(select * from dept where dept.deptno = emp.deptno)
标量子查询:子查询只返回一个元组的一个一个属性。
- select,order by子句中只能出现标量子查询 。
- from中的子查询必须有别名。
- group by子句中不允许出现查询语句,其他地方都可以出现子查询。
- with as语句将定义好的查询作为子查询嵌套在其他语句中。
视图
-- 创建视图
create view viewname as
select *
...;
视图是固定好的一些查询。将查询结果固定为视图。
视图中并不储存数据,知识储存怎样获得这些数据,因此对源数据的更改也会更改视图,同样,对视图的更改也是直接更改源表的数据(更改并不一定能成功,如果视图包含了所有的not null属性的话才可以成功)。删除视图不会删除源数据。与with as相比,它是固定储存的。视图也被称为伪表。
视图还可以用来实现权限控制,来使得特定用户只能看到表的一部分。
DCL
控制表的读、写、删改;数据库的创建、更改、删除;对其他用户的赋予权限等各类操作。
-- 赋予权力
grant power/group to usename;
-- 收回权力
revoke power/group from usename;
关系代数
SQL内部把SQL语句转换成对应的关系代数进行具体的查询操作。关系代数有三种运算符:基础运算符、附加运算符和扩展运算符三种。
基础运算符
-
select 选择$\sigma_{P}(r)$: P是选择条件,r是目标。P里可以有$\and \or \neg$的逻辑运算,但是不能出现关系代数表达式,即不支持嵌套子查询。
-
project 映射$\Pi_{A1, A2, A3}(r)$: 相当于语
select A1, A2, A2 from r句,但是不完全等价,不能进行数学运算,且默认去重,是严格集合。 -
union 并$\cup$: 对应 union语句。
-
set difference 差$-$: 对except/minus语句
-
Cartesian product 笛卡尔积$\times$:
-
rename 重命名 $\rho _a(emp)$: 相当于
emp as a语句更名操作。
基础运算中的一元运算有 选择,投影,更名三种。
附加运算符
简化某些常用操作,不增将关系代数的表达能力;
-
Set-Intersection集合交 $\cap$: $r\cap s = r - (r - s)$
-
Natural-Join自然连接$\Join$: natural join。
-
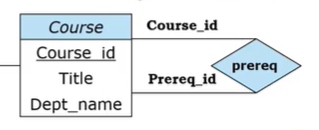
Division $\div$: 除运算是一大特色。$A\div B$的效果是:如果有A中的除B中属性外的元组对应了B中所有的属性,那把这部分拿出来就是答案。具体如图:
-
Assignment 赋值$\leftarrow$: 相当于with as
-
外连接: 左外连接和右外连接和全外连接加横杠
latex打不出来,我太菜了。 左外连接等价于$(r\Join s) \cup(r - \Pi(r\Join s) \times{(null, …,null)})$
扩展运算符
- 广义投影:支持对属性进行数学运算的投影
- 聚集函数 ${P1, P2}\mathcal{G}{F1,F2}(r)$: 等价与SQL中的
select F1(), F2() from r group by P1, P2,F等可以为min,max,sum,average…
- 聚集函数 ${P1, P2}\mathcal{G}{F1,F2}(r)$: 等价与SQL中的
选择:下列操作在SQL语言的查询过程中,最后一个执行的是?( A )
- A select
- B from
- C where
- D having
数据库设计
ER图
ER图也是一种数据模型,拥有数据,数据联系,数据语义,一致性约束四项。
实体时现实中的物件。实体集时在相同环境下具有相同属性的抽象集合。
ER图实体集与联系集之间的充当的角色一般情况下不用标。但是,对于实体集自身与自身之间的联系,需要显式地标注角色 role。
约束
映射基数 Mapping Cardinalities:联系集是几对几的联系。有一对多,一对一,多对多。
在ER图中,联系集有箭头指向‘一’的一方。
参与约束 Participation Constraints:两个实体集在关系中的参与程度可能不同,有部分参与和全部参与。
在ER图中,联系集使用单线联系部分参与,双线联系全部参与。
主键 Key:实体集的Key容易决定。对于联系集的Key,根据映射技术生成相应的key。 在ER图中,主键使用实线下划线识别。
去除冗余
联系集生成Key的过程中产生了很多冗余数据(即一个数据出现了多次)。在这一步中会删除重复数据。
但是,对于某些实体集,在删除冗余数据后,剩下的属性无法构成唯一识别码(主键)了。这样的实体集称为弱实体集。它不完整的主码称为分辨符,使用虚下划线识别。 在ER图中,弱实体集与强实体集之间的关系是双菱形框。
逻辑设计:生成关系模式
在ER图行程中做去除冗余的操作,但是对于关系模式,很多数据的冗余是必要的,会添加回来。
复合属性:拆分属性。
多值属性:与主键拿出,单独成表。
弱实体集:将对应请实体集的主码拿出来
联系集:
联系集的属性包括相连实体集设计到的主键和自身的属性。进行合并后,得到的最终结果:
- 一对一:联系集并入任意一个实体集,使用实体集的主码做主码。
- 一对多:联系集并入一的一方,使用‘一’的主码。
- 多对多:联系集单独成表,使用实体集主码的并集作为主码。
物理设计
目标:响应时间小,空间利用率高,事务吞吐量高。
Index 索引
生成类似目录树的方式来来实现快速查找(类似分块查找,常使用B+数)。
有序索引:索引与属性一一对应,且有序排列。
建立索引需要代价,通常为 1. 经常访问 2. 经常求最值 3. 经常出现在join等值比较中 这三类属性建立索引来加快查找。使用索引查找同样需要代价,是否使用由本次执行的吞吐量决定。
Hash索引:使用hash函数来计算得到索引,无须有序排布,查找很快。
hash索引没有顺序,区间操作复杂度较高。但是当属性经常用于等值比较,且满足下列条件之一时比较适用:
- 数据库表时static,不更新的
- DBMS(数据库管理系统)提供了动态的hash方法
Cluster 聚簇
把属性值相同的数据放到一起,方便一起操作。
对于 1. 有大量重复数据 2. 属性经常出现在等值比较 3. 经常出现在等职连接 的属性可以考虑建立聚簇。聚簇的代价非常高,要谨慎建立,插入/删除操作会破坏聚簇。
函数依赖
依赖关系
主属性:包含在任意一个候选码中的属性
第一范式:所有的属性都是原子的
第二范式(被忽略了):非主属性对主属性的部分依赖(部分主属性不能推导出非主属性)
第三范式:去除非主属性对对主属性的传递依赖(非主属性不能推导出其他属性)
BC范式:去除主属性之间的传递依赖(即部分主属性也不能推导出其他主属性)
若R属于BCNF,则R有:
1、所有非主属性对每一个码都是完全函数依赖。
2、所有的主属性对每一个不包含它的码,也是完全函数依赖。
3、没有任何属性完全函数依赖于非码的任何一组属性
寻找所有的候选码
将属性分类:
- L类:属性只出现在左边,一定在候选码中
- R类:属性只出现在右边,一定不在候选码中
- N类:属性没有出现,一定在候选码中(只能自己推自己)
- LR类:两边都有出现,没有一定的情况。
如果所有的L属性成功构成了候选码,则为此关系的唯一候选码,不存在其他候选码了。
依赖关系不是离散数学的蕴含关系。即$A\rightarrow BC \Leftrightarrow A\rightarrow B \and A\rightarrow C$。
BCNF分解算法:
输入:关系R0和其上的函数依赖集S0
输出:由R0分解出的关系集合,其中每个关系均属于BCNF
方法:下列步骤可以被递归地用于任意关系R和FD集合S。初始时,R=R0,S=S0。
-
检验R是否属于BCNF。如果是,不需要做任何事,返回{R}作为结果。
-
如果存在BCNF违例,假设为X→Y。计算X+。选择R1=X+作为一个关系模式,并使另一个关系模式R2包含属性X以及那些不在X+中的属性。
-
计算R1和R2的FD集,分别记为S1和S2。
-
递归地分解R1和R2。返回这些分解得到的结果集合。
剩余部分
查询优化与处理 Query process and optimization
处理
- 查询分析 analyses ,有词法分析(关键词,表明存在)和句法检测(语法正确)
- 查询检查 check,查看用户权限,是否满足约束
- 查询优化 optimization,代数优化和物理优化,比如对于同一个功能有不同复杂度的实现方式
- 查询执行 execution,优化后最终得到代码
判断:当一个查询语句的查询条件中涉及A属性,同时A属性上已有索引,这个时候利用索引进行查询会提升查询效率 (√) 数据量大时,使用索引效率降低
优化
不考虑CPU,memory的时间,只考虑IO时间。
代数优化:利用关系代数的等价变换得到最优的关系代数。
根据硬盘块大小和数据量计算读写操作的次数,要求次数越少越好。最好的方案是先做选择,再做连接,而且不建议使用笛卡尔积连接。
判断:对于代数优化过程中,应该尽量把选择操作放在后面 (❌) 放到前面
物理优化:优化存取路径,有三种策略。
- 启发式优化(大部分情况适用,去掉不合理的查询)
- 基于代价计算的优化(计算量大)
- 混合式的优化(一般选择)
数据库对主键一般做了索引。当返回量大于10%时,不适用索引,否则使用索引提高效率。
Transaction 事务
事务应该具有的四个特性ACID:
- 原子性 Atomicity
- 一致性 Consistency
- 隔离性 Isolation
- 持久性 Durability
数据库处理操作时是以事务为单位的。事务有几种状态:
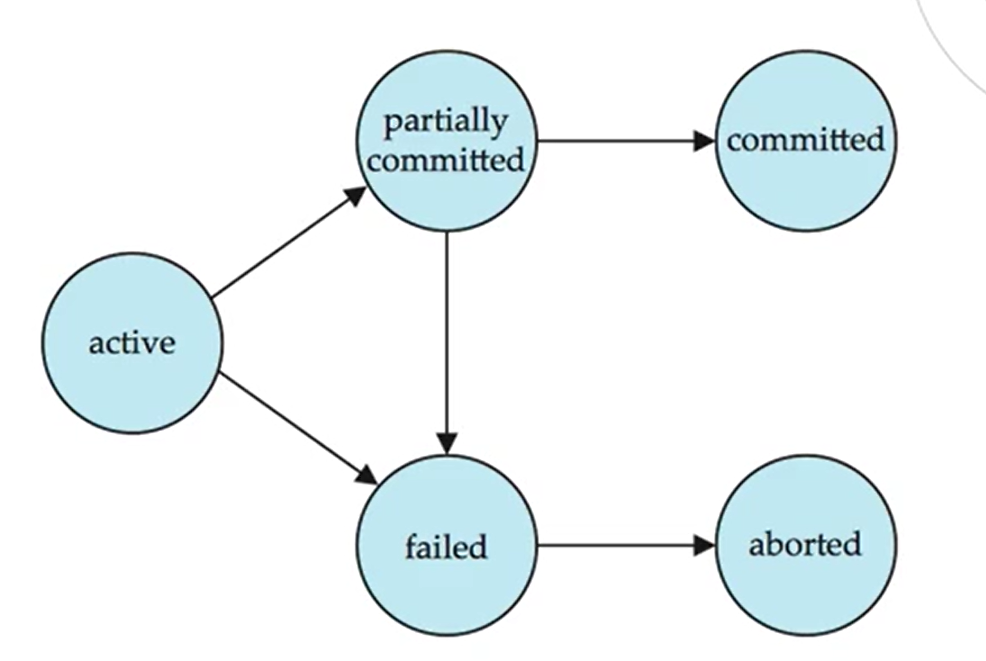
- Active: 事务刚刚打开
- Failed: 某条语句执行错误,无法继续
- Partially committed: 最后一条语句执行成功,但是还没有写入硬盘
- Aborted: 因为执行失败而回滚后的状态
- Committed: 事务执行成功
数据库可以多用户并行。但是为了保证一致性,会给数据加锁,再数据被更改后,其他用户无法对数据进行更改操作。(再committed之前,其他用户看到的仍然是之前的数据,但是无法更改)。
为了满足一致性(比如外键约束),有些语句单词执行插入不进去。但是,可以在定义表的时候加上DEFERRABLE INITIALLY DEFERRED来让一致性检查推迟到commit时(默认在执行DML语句后立即检查)。则在事务之间可以暂时不满足一致性约束。
有关事务的语句:
commit -- 提交
rollback -- 结束当前实物并回滚,默认撤销本次所有更改
rollback to savepoint -- 回滚到保存点(可提供名字参数,默认回到最近一次)
恢复系统 Recovery
保证故障的时候数据不丢失。DBA的职责,与开发人员无关。如容灾,即在很远的地方做数据备份,防止备份数据同时损坏。
事务故障:加载到内存中的数据,在某次事务中的错误。如找不到数据/内存溢出,影响范围较小。
系统故障:硬件发生问题,如数据库的操作系统故障导致内存数据丢失。
磁盘/介质故障:磁盘物理损坏/错误。
存储结构
数据时间越久,价值越低,也会被保存在其他如磁带的廉价介质上。存储器的种类主要有:
易失型 Volatile:速度快,不稳定,如memory,cache
不易失 Nonvolatile: disk, flash
稳定型:Stable:如磁盘阵列,支持热插拔,但是不能处理远程容灾。
在数据传输过程,有三种状态:
- Success 成功
- Partial failure 部分失败:两块会不一样,用一块的数据替换另一块
- Total failure 完全失败:目标块时完好的
Input: disk-> memory
Output: memory->disk
日志
数据库有日志(redo log)储存记录,可以通过检查用来恢复。记录的内容有:
1、 事务的标志 2、 数据项的标志 3.、数据项的新值和旧值。
memory中既有数据的缓存,也有日志的缓存,积累到一定量后写入disk。
在写入时,日志优先,优先写入日志再进行操作。
检查点 checkpointing:讲所有日志redo or undo 消耗大量时间,也没必要,因此数据库设置检查点。
强制将memory中的数据写入disk,保持两边的数据一致。可以根据日志中的检查点记录来决定恢复操作。
备份和恢复
备份策略: entire/portion
备份种类: 所有信息备份/只备份更改过的数据
备份模式: Offline(cold, consistent) 和 Online(hot, inconsistent)
恢复模式: 完全/不完全
并发控制
并发下的可能问题:
Lost update丢失更改;T1,T2都在原来的基础上进行修改后提交,会有一个的更改背覆盖掉。
Non-repeatable read不可重复读:T1读完数据,T2修改,T1再次读后数据不同了。 Phantom read 幻影读:数据插入/删除,强调数据变化
Dirty data脏数据:T1新型修改,T2读取修改后的数据,T1撤销更改,T2使用错误数据。
填空:事务的并发主要破坏如下事务的(隔离性)特性
事务隔离性的级别分类:
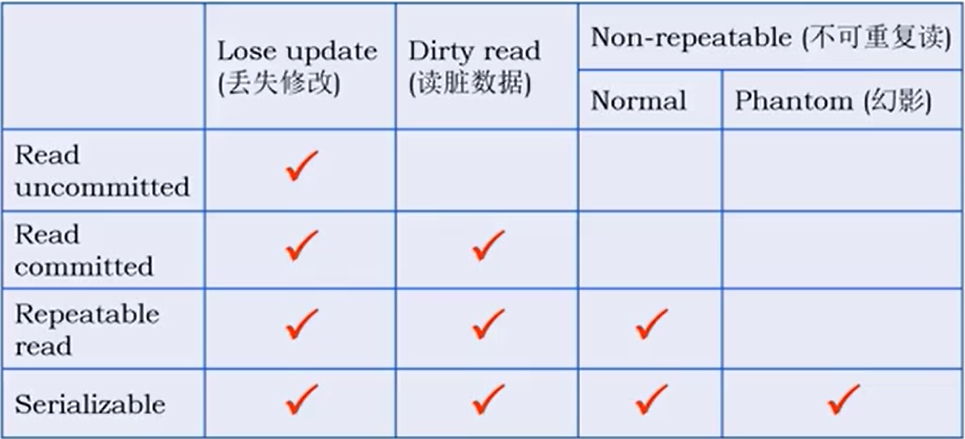
- 未提交读:其他事务的修改都能读到,产生脏数据
- 已提交读:只能读到其他数据已经commit的数据,会发生Non-repeatable read问题。
- 可重复读:存在事务操作数据时,其他事务都不能修改数据。但是幻影读问题仍然存在(只阻止对正在操作数据的更改,但是插入仍可以插入新数据)
- 序列化Serializable:所有的事务必须一个一个进行,不能并发。
四种隔离级别都不能同时写,不会发生lost update问题。
Lock and lock protocol
使用加锁来确保隔离性。根据应用场景,分为共享锁(读锁)和排他锁(写锁)。有共享锁时其他事务也可以加共享锁,但是不能加排他锁。有排他锁的形况下不能加锁。
根据加锁和解锁的时机,将封锁协议分为以下三种:
- First level:在写之前加锁,写完解锁。对读不做限制。没有解决Non-repeatable read没有解决Dirty data的问题。
- Second level:读数据前加锁,读完数据解锁。可以解决读Dirty data的问题,但是仍然解决不了Non-repeatable read的问题。
- Third level:事务开始时加锁,但是读完不释放,事务结束时才释放。解决了Non-repeatable read的问题
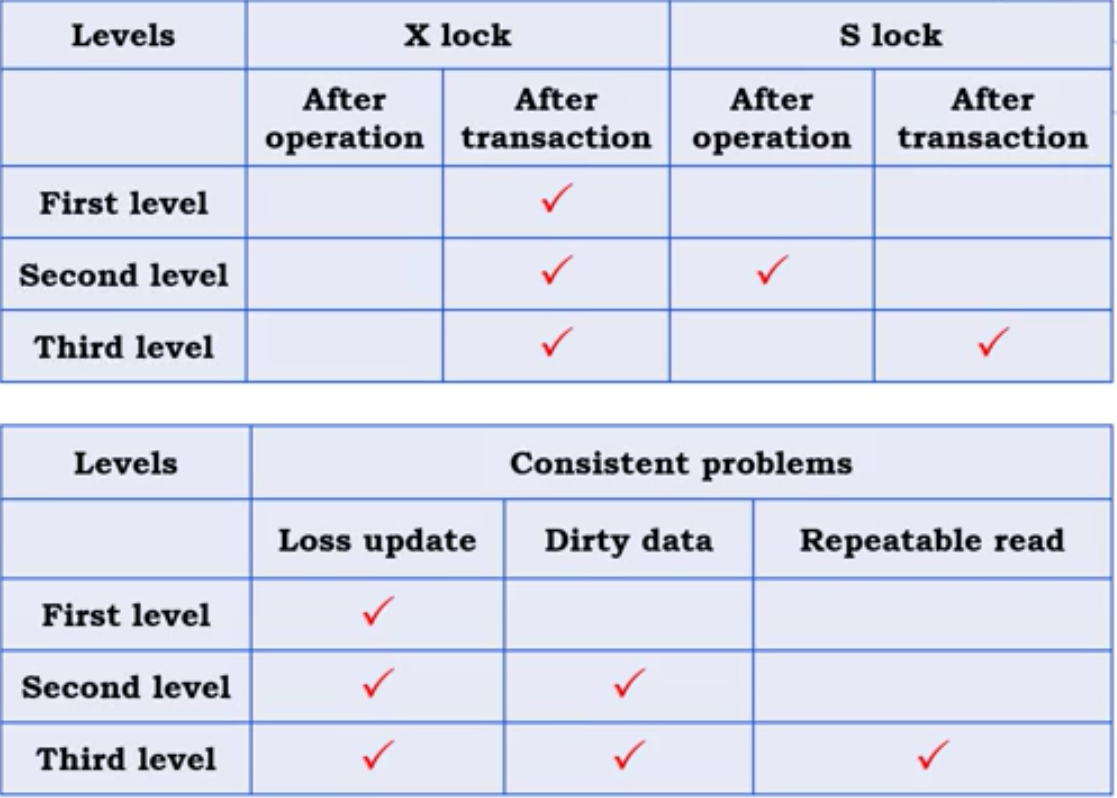
Live-lock and dead-lock
live lock:活锁(饥饿),始终得不到锁。可以使用FCFS策略解决。
dead lock:死锁。有避免和诊断-接触两种策略。
死锁避免:
- one-time block:要么一次获得所有锁,要么不获得锁。解决了问题,但是效率很低
- Ordering block:加锁按照固定的顺序进行。但是维护成本也很高。
死锁检测:
这种方法更为常见。使用等待图方法识别。
在检测到等待图中有环时,采取策略来消除掉死锁。策略未选择一个事务,强制roll back。
在等待图中发现多个回路,系统将选一条(C)的回路进行破坏。
- A创建时间最短的
- B关联数据项少的
- C产生代价最小的
- D关联事务最少的
Concurrent scheduling 并发调度
可串行化 Serializability是检测并发调度正确性的唯一标准。 具体指当前的并行操作,能否更改为穿行操作而不改变结果。
冲突操作:对同一数据的读-写、写-写操作会产生冲突,不同的执行顺序结果不同。
对于冲突操作,必须按照特定顺序进行,否则结果会不一样。
两段锁:
采用两段锁协议能保证数据库的操作是可串行化的(充分条件)。两段锁协议指:
- 保证事务在读写前一定获得锁
- 事务的锁在事务不会再申请锁以后才会释放(事务结束)
两段锁协议是弱于一次性锁的一种协议。同时,满足Third level协议,也是一定满足两段锁协议的。
判断:满足一次性封锁协议一定满足两段锁协议 (√) 两段锁协议要弱于一次性锁协议的
Multiple granularity protocol
多粒度加锁协议。
比如,可以给某行加锁,可以给某表加锁,或者整个数据库加锁。这是可以动态变化,对不同的事务实行不同的封锁的。
这样,就会存在隐式锁。即,对一个数据库的节点加锁,其下属节点都会被隐式封锁。这样,在对一个节点加锁时,还需要向上考虑所有的祖先节点是否有冲突,向下考虑所有的子孙节点是否有冲突,代价非常高。
intention lock 意向锁:一个节点有意向锁,则在加锁时它的祖先都会被加锁。
意向锁有意向共享锁,意向排他锁和共享意向排他锁。只有当父节点有意向共享/排他锁时,才能给节点加共享/排他锁。