计组期末复习
目前未知的六次作业,前四次是数据的存储(整数1,2、浮点数3,4),第五次是汇编指令与C编码的关系与转换、第六次是内存大小的计算方法(机械硬盘和DRAM内存)
整体目录
[TOC]
复习重点:
- 小题占30分(20分选择,20填空)、涉及PPT的所有细节
- Two different kinds of CU
- IO module和外设:问题,I/O到底可不可以直接连到外设上
- IO Technology :三种不同方式的具体细节,重点关注中断
- 浮点数:可以无缝衔接的原因、进制转换
- Memory Expansion:位扩展、字扩展、同时扩展
- BUS architecture:不同速度的设备使用怎样的架构
- Instruction addressing mode:不同寻址方式及其优缺点、在那种情况来使用
- Memory Capacity: SDRAM容量计算(数据总线、地址总线-复用、片选总线)
习题课问题:
- CH4.3 26页是怎么看出是小端的?
- CH4.3 28页 栈帧具体做了什么?
- 流水线M阶段阶段操作到底执行了什么Memory和write back有什么差别?
Chapter 1: 简介
大小端问题
小端按内存增大的方式储存,即低位在前、高位在后。大端则是相反的高位在前、低位在后。但是具体在物理内存上的位置的未知的。上述的内存增大是指储存这个数据的内存。如0xabcd,0xab一字节,0xcd一字节。在小端中,计算机把0xcd存在低地址、0xab存在高地址。而大端则是那0xab存在低地址,二八0xcd存到高地址中。(我们平时的阅读顺序时大端顺序,即从左往右)
Chapter 2: 信息的表示和计算
使用补码进行保存和计算的原因是因为补码可以保证运算正确却是一个Abel群。
无符号/有符号整型之间的转换规则是二进制形式保持不变
IEEE 754标准
浮点数的表示:$(-1)^s\times M*\times2^E$
但是,计算机在储存时不仅仅保存s,significant位M和exponent(阶码)E,而是做了一些调整。
| S(1/1) | Exp(8/11) | Frac(23/52) |
|---|---|---|
| 符号位,与s相同 | exp filed encodes,不等于阶码 | frac field encodes,不等于M |
float类型和double类型的精度主要区别在Frac位的保存上。
三种不同的编码形式
(在计算机内同时使用,应用于不同大小范围的数字)
Normalized 规格化数
最常用的类型,用于储存大部分数字,不能储存非常小和无穷的数字
特点:Exp位不等于0或255。
Exp位是偏置(Biased)储存的,偏置$bias=2^{k-1}-1$(K是exp位的位数(8或11))。储存方式是$E=Exp-Bias$
Significant位在编码时默认忽略了开头的1(1.xxxxx)。
De-normalized 非规格化数
用来储存非常小,接近0的数字
特点:Exp位全部为0。
由于Exp位的结果位0,如果依照上面的偏置规则来看,E位应该为0-Bias。但是并不是,我们对结果做+1处理。所以实际上$E=1-Bias$。(为了使计算机在计算的时候不同特殊处理,无缝衔接。功能等同于储存整数是的补码处理)
而Significant位则默认省略了0(0.xxxxx)
Special Values 特殊情况
Exp位全为1,而frac位全为0时代表一个非常大的数(超过储存范围,∞)
而同时,frac不全为0代表出错了,结果不是数字
PS:非规格化数不以规格化数储存的原因之一是因为数字太小,继续去增大M,储存E的位数就不够用了。
PS(无缝衔接的原因):非规格化数对E做加1处理、最大的非规格化数和最大的规格化数非常接近
Chapter 3:指令编码和指令集
设计指令集需要的点:
- 操纵数种类 Operation repertoire
- 数据类型Data types
- 指令形式 Instruction format
- 寄存器个数
- 寻址方式
Types of Operands

Imm(%ebp) 取该地址的内存偏移imm位
指令不能使数据直接从内存到内存转移。
寻址方式
- Immediate //立即数:直接存数据
- Direct //直接:直接存数据的的地址
- Indirect //见解:存数据地址的地址
- Register //寄存器:存数据的寄存器编号
- Register Indirect //寄存器间接寻址:存数据寄存器编号的地址
- Displacement Addressing //基址寻址:存到操作数地址的到基准的距离
- Relative //相对寻址
- Base-Register //基址寄存器寻址:寄存器里储存了偏移量
- Indexing //变址寻址:储存指向偏移量的数据·的地址
如何区分:Opcode的前几位是mode field,表明了寻址方式
如何设计指令集?
- Instruction Length
- Allocation of Bits
- Number of addressing modes
- Number of operands
- Register vs. memory
- Number of register sets
- Address range
- Address granularity
使用指令
这里的指令的顺序同计组实验时的清华实验箱的指令顺序相反。
指令集分类
CISI:复杂指令集(intel、AMD)
Traits
- 每条指令执行更多的操作
- 程序更小
- 占用空间更少
Why need RISI?
-
编译器开始流行
- 很多指令使用频率很低
- 一些复杂的指令执行得很慢
RISI:精简指令集
Traits
-
Small, highly optimized set of instructions
-
Uses a load-store architecture
-
Short execution time
-
Pipelining
-
Many registers
Advantage:
- Less transistors needed in RISC//需要的晶体管较少
- RISC processors have shorter design cycles //设计周期较短
- RISC instructions take less clock cycles than CISC instructions//执行周期较短
Chapter 4: Processor Architecture
Organization
Y86是作者自己构想的一套处理器、并没有在现实中使用。
在设计处理器的时候,一般需要考虑四个方面:使用者(Coder and Complier)看到的模块、寄存器的组织、指令集的设计和指令的编码和译码。
Instruction has initial byte, spiting into two-bit parts: i-code and i-funtion
Processor Implementations
Five Stages
-
**Fetch **(取址F)
Extract the
i-codeandi-funFetch register in
RAandRBFetch a 4-byte constant word in
valCcompute
ValPas the next address of instructions -
Decode (译码D)
Read up to 2
oprandsfrom the register file asValAorValB(for some instructions, it reads %esp rather than rA and rB) -
Execute (执行E)
the result as
valE -
**Visit Memory **(访存M)
if we read value, it was
ValM -
Write back (写回W)
-
PC update (更新PC)
Instruction Pip-line(流水线及优化)
SEQ(顺序执行)的缺点:Low Throughout(吞吐量低), Wast Resources(浪费资源), and Big Latency(延迟高)
Pipeline(流水线)的特点:有效增加了 throughout(The number of customers served per unit time), 但是同时也增加了 latency(the time required to service an individual customer)
latency的组成:Latency主要由Combinational logic和register两部分的延迟组成。而流水线将Combinational拆分,增加了register部分的延迟,但是收获了较大的吞吐量。</br> 但是显然,拆分的数量影响着流水线的效率。当拆分过多时,增加的register延迟太高,反而会导致整体吞吐量的下降。
Y86的流水线实现:
将PC更新调整为一个周期的第一个阶段。流水线一共有5个周期
- F:hold PC的下一个值
- D:介于Fetch和decode中间,hold decode要使用的fetch得到的信息
- E:decode和execute中间,hold decode得到的信息和寄存器读出来的值
- M:execute和memory之间,hold指令执行得到的结果
- W:memory和feedback之间,在执行ret操作后,该阶段把结果存入寄存器,同时将地址信息返回给PC用于计算下一条指令的地址
Pipeline hazards(流水线缺陷):
- Data dependency(数据依赖性)
数据依赖性会发生在很多地方:
Register:数据缺陷发生在一条指令写入信息,一条指令读取信息。但是可能上一条指令的M阶段还没有执行,这条指令就要实行D阶段了,因此会读取到错误的信息。
PC:PC还没有被正确更新,下一跳指令一键要执行F阶段了,发生冲突
Memory:同Register
Condition Code:在jmp等指令执行前,还没更新Condition
Statue Register:同Condition code
Avoiding(避免流水线缺陷):
流水线的avoiding是在硬件层面实现的。虽然在代码中加入nop空转指令也可以达到相同的目的,但是这要求做额外的代码工作,不太讨论范围中。
最常用的方法就是stalling(等待),等到前面的指令执行结束在执行就可以了。例如在指令间插入bubble来延缓下一条指令的执行。
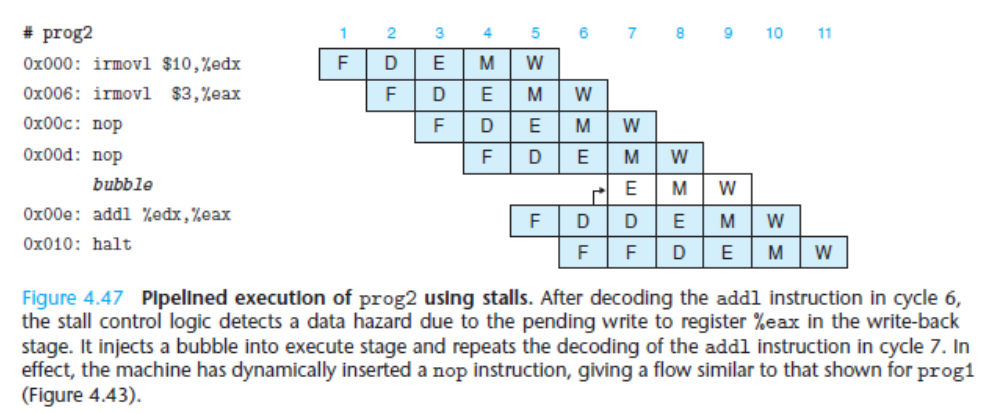
Stalling的缺点也很明显——浪费时间
当然,也可以使用Forwarding方法来避免冲突,即通过管道,间吓一跳指令要使用的值预先传递下去,而不是等到M阶段再储存。
Forwarding的缺点在于,需要添加很多额外的信号和寄存器来完成操作。
一些其他的东西:
对比Jxx,Ret,Call三个指令,Call指令不会引发pipeline hazards,因为Call指令的PC计算在取指阶段就已经完成了,而Jxx和Ret则分别在PC update和Memory阶段才确定
Chapter 5: Memory
Memory Hierarchy(内存的层级)
不同的储存介质的速度、容量和价格有着明显的区分。他们之间的层级关系是计算机结构的核心之一。
Storage technologies and trends
Read Only Memory(ROM):
更Non-Volatile(稳定)一些,种类跟多,如:
ROM: 掩模型,永远无法改变,数据在制造过程中写入。
PROM:可编程型。可以编程一次,之后保险丝断裂,变成只读。
EPROM:(Erase Programmable),经过紫外线照射可以查出数据重新写入。
EEPROM:电子可擦除,比较稳定,用来保存一些断电时的少量信息。
Flash Memory:常见的手机内存卡的介质。相对于(EEP)RAM来说,读写快,容量大。相对于RAM来说要更稳定。但是进行1000,000左右的读写后就会失效。
Random Access Memory:
比较Volatile(不稳定),用在Cache(SRAM)和内存(DRAM)。RAM通常被封装成芯片,由cell(大小1 bit)组成,多个芯片组合成出储存器。
Static RAM:
每个cell的实质4/6-晶体管电路。在通电条件下信息可以永久保存,抵抗电子辐射等干扰的能力较强。同DRAM相比,速度和价格会高很多。
DRAM:
DRAM的每个cell是电容,用一个晶体管来访问。由于电容会不断的损耗电量,因此需要不断的进行充电(per 10-100ms)。同时对电子干扰很敏感。速度比SRAM慢,但是比较便宜。
Key Characteristic of Main Memory(一些重要的特征,如容量计算和扩容方式):
Capacity:储存的容量指的是他能储存的二进制位数。由公式$Capacity=NumbersOfUnit\times Word$计算得到。
Convertional DRAM Organization:
DRAM一般命名为d×w 型,意思是有d个supper ceil(单元),每个ceil储存了w bit数据。
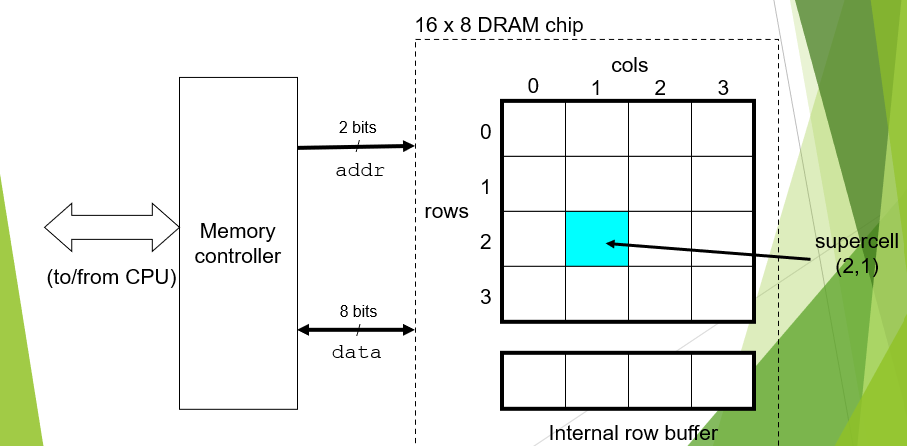
在读取数据是,有地址总线传入地址信息,由数据总线将目标数据传出。传入地址时,行地址和列地址分开传送,因此总线可以复用。而数据信息则是一次传出,没有复用。
如上图中的16×8 DRAM chip,有两根地址总线,分别传送二位2进制(十进制4)的行和列信息。而数据总线有八根,传送八位2进制的数据。
在制作内存条是,有多片DRAM并列放在一起(如下图)。但是在读写时,并不是按照一片一片的顺序进行的,而是每次同时读所有chip的相同位置(就是竖着读写的)。因此为了找到目标数据所在的ceil,还需要片选总线。
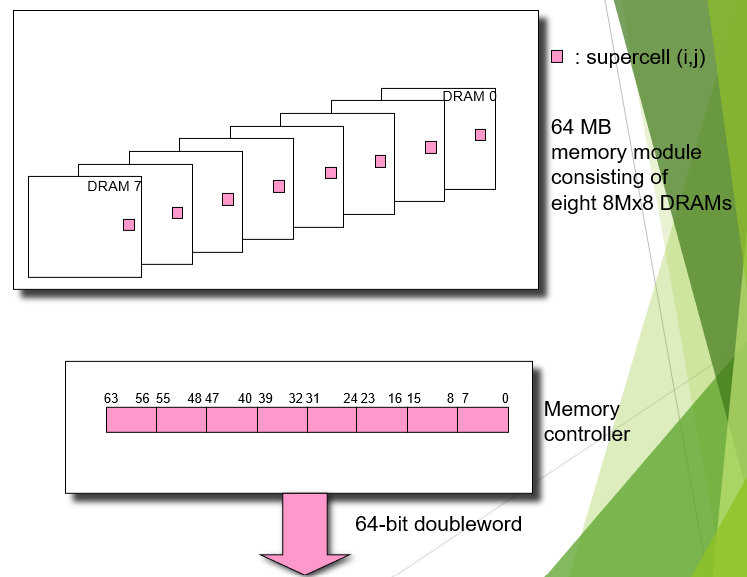
Read/Write Transaction:
CPU和Memory以I/O Bridge为媒介,通过控制总线、地址总线和数据总线来交换信息,进行memory的读写等操作。
Memory Extension(内存扩展):
Word(字长):在此处指的是单片芯片的容量(及总地址的大小)
Bit(位长):指的是每次取数据时取的长度
在计算机的内容不足时,为了扩展内存我们需要将多组芯片串到一起。而在硬件上处理时,就有几种不同的方案。比如当前计算机使用的是一片$1k×8$位的芯片,现在需要将内存扩大一倍。
当前状态下,需要8根数据总线(Bit长度为8位)、10根地址总线(总共1K的储存单元)。
位扩展:每片芯片的字长不变(1K),将每次选取的数据的位数扩充一倍,数据总线变成16根,得到$1k\times 16$的芯片。
字扩展:不改变位长,而是增加总的地址数量,增加一根地址总线,得到$2K \times 8$的芯片。
字、位同时扩展:两个扩展方式可以同时进行(在总线的数量足够的情况下)
Disk(硬盘)
这里的硬盘专指机械硬盘。机械硬盘由若干个Platter(盘片)重叠而成,每个Platter由上下两个Surface(盘面),盘面上有若干个同心圆环状的track(磁道),而Surface也被等分成了若干个Sectors(扇区)。
Capacity:计算硬盘的容量,首先要知道每个Sector的容量,每个track的Sectors数量(对所有的磁道来说为一个定值)和每个Surface上tracks的数量以及Platers的数量,进行乘法计算即可。
Disk Access Time:
在访问某一块的数据时,read/write head(读写磁头)先根据地址移动到对应的磁道,接着等待匀速转动的磁盘转动到对应的扇区,然后进行读写。因此磁盘的读写时间包括三部分,及seek time(寻道时间)、rotational time(等待旋转的时间)和transfer time(数据传动时间)。而磁盘在读取时,总是每次读取完整的一个Sector。
Tavg seek:平均寻道时间,一般为题目给的定制,与制作工艺有关
Tavg rotation:平均等待时间,与磁盘的转速(RPM)有关,计算方式为磁盘旋转一圈的时间的一半。
Tavg transfer:数据的读取时间,为磁盘旋转过该扇区的时间,同rotation time相比很,可以忽略。
机械硬盘的速度比S/DRAM的速度慢的多大概为SRAM的40,000倍,DRAM的2,500倍。
Solid State Disk(SSD固态硬盘)
特点:以units of pages为单位进行读写,每次写入前需要擦除整个pages,100,000次擦除后损坏。
固态硬盘随机read的速度比顺序read要慢一倍左右,随机write的速度却会比顺序write要慢十几倍。因为随机写入时,擦除一个界面时要花费大量的时间,同时还要备份没有更改的部分数据。
速度上,SSD比机械快得多,当时也贵得多,然而依旧比DRAM慢得多(所以啊,打游戏慢的话还得换大内存啊,SSD解决不了多大问题!——林老师)
Locality of reference(访问局部性)
有时间的局部性和空间的局部性。
Temporal locality(时间局部性)体现在是使用相同的内存时,由于cache的存在,速度会比随机访问快得多。
Spatial locality(空间局部性)体现在访问临近的内存时的速度更快
在写程序时,考虑到时间局部性和空间局部性,能在相同的时间复杂度上使程序拥有更快的速度。具体原因与计算机的cache机制有关,在后面讨论。
内存结构中的cache(简单介绍)
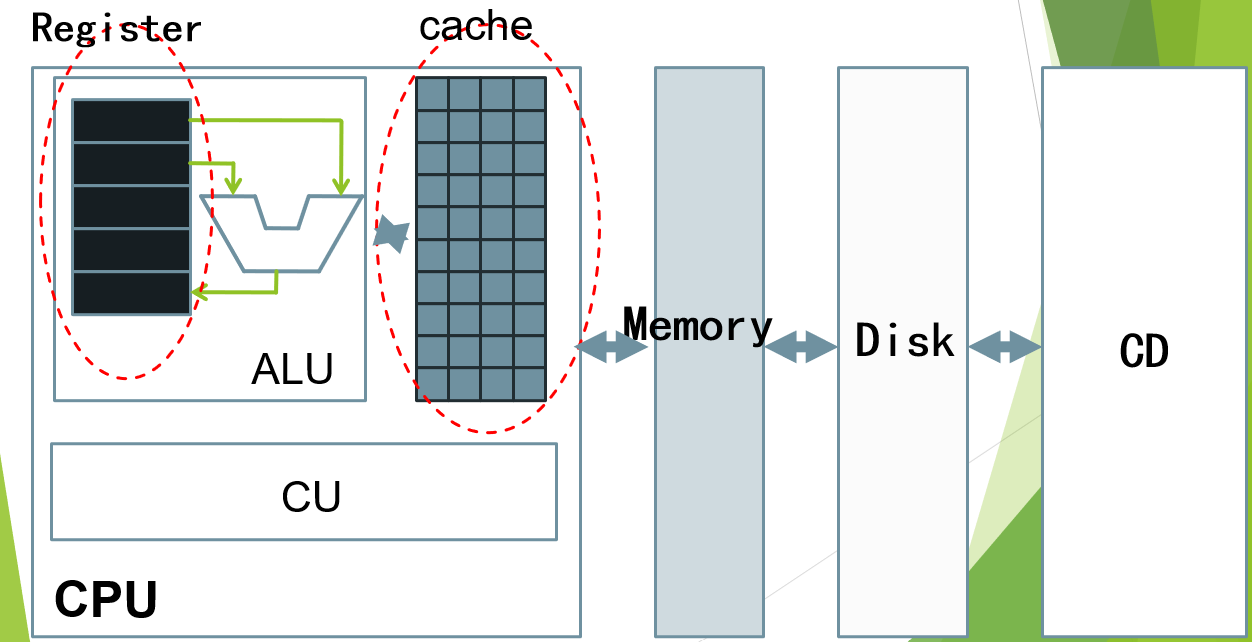
cache缓存了Memory的一部分。在访问内存时,优先在cache中查找。能找到的话(hit)直接访问cache速度要快得多。而找不到的话(miss)则要直接从内存中读取,速度会慢得多。
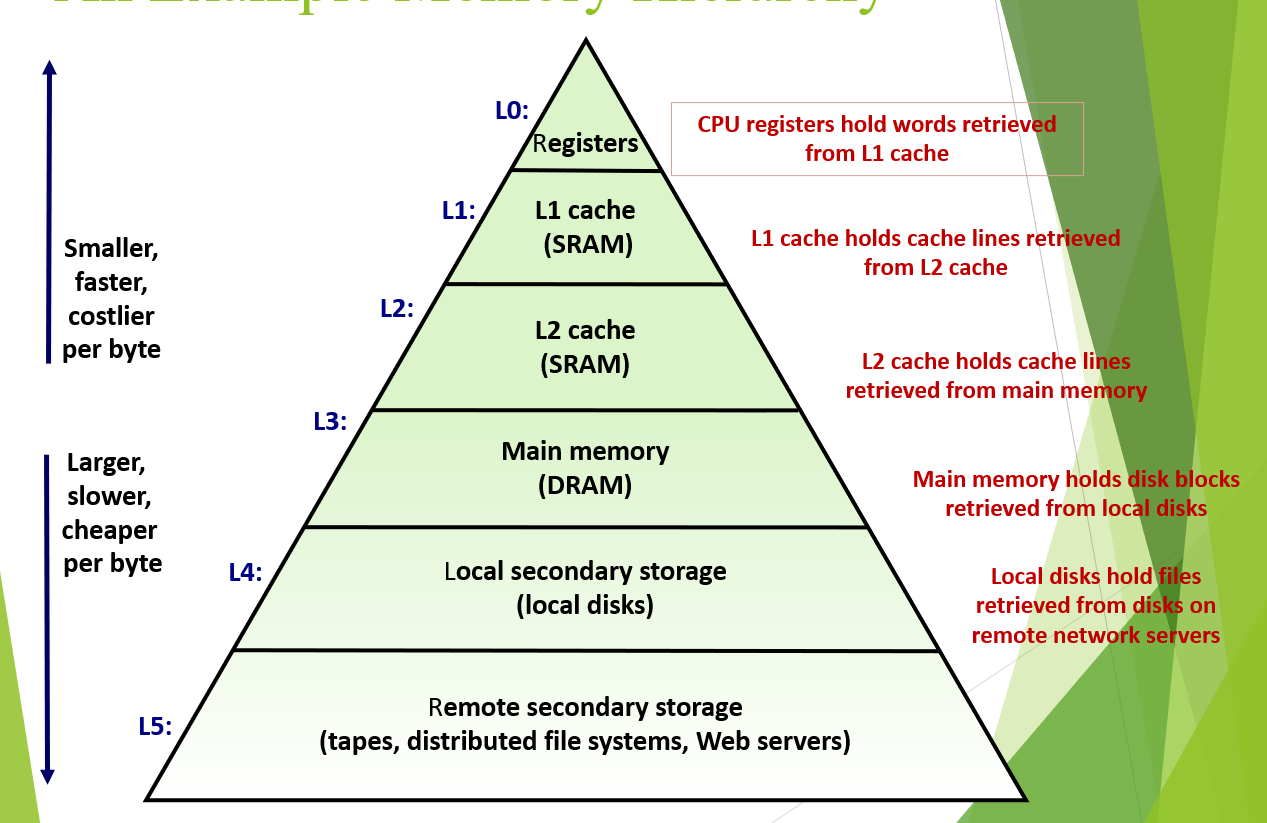
计算机中最重要的结构之一。层级越往上访问速度越快,价格越贵,越往下访问速度越慢,价格越便宜。使用越频繁的数据放到上层,使用没那么频繁的放在下增,保证价格低廉的同时有很快的处理速度,使得计算机走进千家万户。
Types of misses
cold miss:系统刚开始运行,缓存区时空的,肯定会miss。
Conflict miss:cache在缓存时有一定的规则,一般缓存去特定的位置会缓存满足特定条件位置的数据。如(只是举例的规则,真是情况规则可能不同)缓存i只缓存memory中每个分块的第i位。这样,但访问的两个数据位于不同分块的相同位置时,每次访问都会冲突(例如0,8在缓存区使用相同的位置,0 8 0 8 0 8这样访问,尽管缓存区未满,除第一次外每次访问都冲突)
Cache(具体实现)
Cache是一种SRAM-based Memory,集成在硬件上,储存了主存的一小部分来实现更快的读写。Cache中储存的是CPU最频繁访问/刚刚访问过的数据。
Cache Organization and operation
Organization:
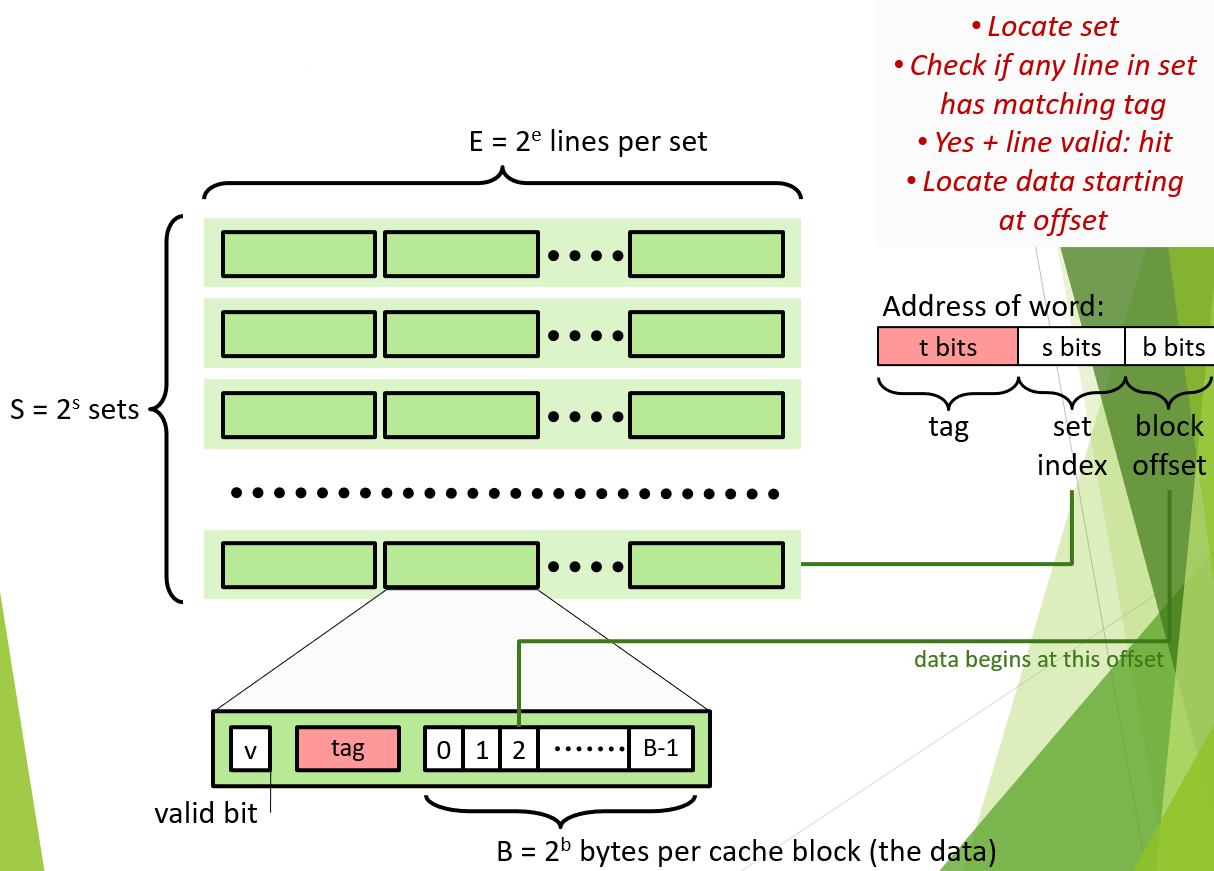
Cache 结构图
Cache是一种S,E,B结构,即有$S=2^s$个sets,每个sets有$E=2^e$列(块),每个块里有$B=2^b$bytes(8 bits)的数据。因此,Cache的容量$Capacity=S\times E\times B(bytes)$。
而每个Block中,分为三部分:valid bit(是否可用),tag()和data(储存的实际数据)。
同时,一个数据的内存地址也可以分为三部分:tag(t bits)、set index(s bits)和block offset(b bits,偏移量)。
Read:
Cache的大小是远远小于Memory的,所以Cash的每个block会对应超过其容量的数据。如何区分这些会使用同一个block单元的数据呢?通过tag位和index位。
在去cache中读数据时,地址的index位表明了这个地址如果被成功缓存会在那个sets里面。依次查看set中的每个block的valid位和tag位。如果valid显示位1(可用)且该block的tag位与地址上的tag位吻合,则说明改bolok中储存的正好就是我们想要读取的数据,此时Cache hit。由于block的data可能不止1字节,接下来使用地址offset位来决定我们从block的第几个字节开始读取数据。如果在上述过程中没有任何一个block满足条件,则Cache miss,需要去memory中直接寻找数据,更新Cache。
同时注意一点,Cache的更新不是以字节位单位的,而是以block位单位的。一旦发生miss,即使改block中储存着其数据的缓存,也会被清除掉。同时,地址上偏移量的二进制大小也就是一个block的data单元的大小(设计决定)。
比如,对于4 bits的地址,$t:s:b=1:2:1$,地址0 00 1,tag为0,最为区分1 00 1和0 00 1两个不同模块的标签;index=0,该数据缓存在set 0中;offset为1为,说明每个block的data块有两字节,而该地址的数据缓存在block data的第1个自己(从0计数)。
问:为什么index位要选在地址的中间而不是高位?
答:为了使得内存中连续的地址不会使用同一个set,Cache能保存的最大连续地址的大小被block的大小所限制。程序连续读写内存时,反而会引发Cache的不断更新,降低效率。
Examples of Cache:
直接相连映射 Direct-Map Caches: E= 1,每个set里面只有1个data block。产生miss直接擦除set,替代。
组相连映射 E-Way Set Associative Caches:$E\geqslant2$,产生miss只会擦除,替代对应的block。
全相连映射 Full Associative Caches: 只有一个大set。此时,对应的地址也只有tag和offset两块了。
Write:
Hit:有两种处理方式
Write-through:直接写回主存中。
Write-back:将数据更新到Cache中,直到Cache被替换更新才将数据写入主存(会有dirty bit,即cache与memory不一致)。
Miss:
Write-allocate:写入缓存区(在多次写入时更优秀)
No-Write-allocate:直接写入主存。
一般要么hit和miss都都写入缓存,要么都直接写入主存,hit和miss时保持一致。
L1层中,在hit的情况下,读写大概花费1-2(5-20 in L2)个时钟周期,而miss后去主存的读取需要50-200个始终周期。因此,$97\%$的命中率实质上比$99\%$慢一倍。
Performance impact of caches
对intel i7芯片来说,$L_1$层cache有32KBi-cache和32KBd-cache(指令缓存、数据缓存),$L_2$层有256KB,$L_3$层8M。而每个block的大小都是64 bytes
Locality:
locality本质上就是增高cache的hit率。以下面的单个计算矩阵乘法$C=A\times B$的c代码为例子,都是三重循环,复杂度都是$O(n^3)$。但是Cache的命中率却不同,从而影响执行效率。(我们假设Cache的一个block中B=32,即能存4个64位数据,同时n很大,存不下多行来方便讨论)
Version 1(IJK or JIK):
int i,j,k;
double sum;
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
sum=0.0;
for(k=1;k<=n;k++)
sum+=a[i][k]*b[k][j];
c[i][j]=sum;
}
}
在最内层的循环中,在矩阵A中,元素时一行一行访问的,misses率0.25(一个block能存4个都变了,每4次更新一次)。在矩阵B中,元素是按列访问的,misses率1.0。而在矩阵C中,元素一个一个访问,只有第一次可能冲突,≈0.0。
Version 2(IKJ or KIJ):
int i,j,k;
double r;
for(i=0;i<n;i++)
for(k=0;k<n;k++)
{
r=a[i][k];
for(j=0;j<n;j++)
c[i][j]+=r*b[k][j];
}
在最内层的循环中,在矩阵A中,元素只访问一个,misses率0.0。在矩阵B中,元素是按行访问的,misses率0.25。而在矩阵C中,元素按行访问,0.25。
Version 3(KJI or JKI):
int i,j,k;
double r;
for(k=0;k<n;k++)
for(j=0;j<n;j++)
{
r=b[k][j];
for(int i=1;i<=n;k++)
c[i][j]+=a[i][k]*r;
}
在最内层的循环中,在矩阵A中,元素按列访问,misses率1.0。在矩阵B中,元素是按个访问的,misses率0.0。而在矩阵C中,元素按列访问,1.0。
对比可以看出,version 2是最优的,version 3是最差的。当足够大时(大于700),version1的每次读写大概需要25个周期,version 2大概5个,而version需要50个以上的时钟周期,差异很大。
Virtual Memory
virtual Memory是一种机制。计算机不能直接使用硬盘Disk里的东西,因此需要先把数据读到Main memory(DRAM)上CPU才能使用。而在使用Disk上的数据是,就存在Virtual Memory这一个操作了。它实际上把运行内存(SRAM)当成了一个硬盘内存(Disk)的缓存来使用了。我们使用的实际数据而空间可以说是Disk上的(但是物理上是操作了Main Memory后再写回)。因此,磁盘上的地址被称为了虚拟地址。
在计算机中,像是嵌入在汽车、电梯等中的卫星控制器一般直接使用物理内存,而PC机,笔记本等现代化设备中广泛使用虚拟地址。
优点:
- Uses main memory efficiently: virtual memory 把DRAM当作了缓存,使它发挥更大的作用。
- Simplifies memory management: 每个程序都能得到“线性空间”
- Isolates address spaces: 程序之间使用各自的内存。不能互相影响。
VM as a tool for caching:
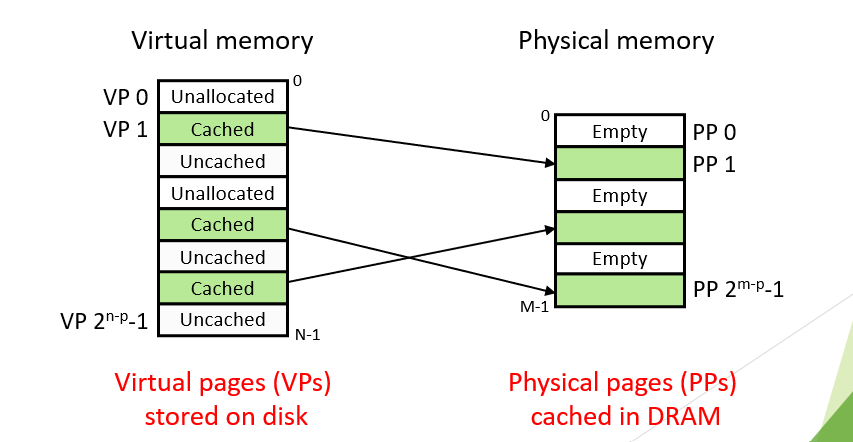
PE和VE的关系和内容对应
虚拟内存是Disk上连续的N个比特块数据。每一个比特块被称为是一个page,大小为$P=2^p$bytes。虚拟内存中的数据有三种,unallocated的就是没有被分配使用的。cached的是已经被分配使用,并且已经缓存到主存DRAM中的数据。而Un-cached的就是虽然被分配给了某程序使用,但是还没有被缓存到DRAM里。
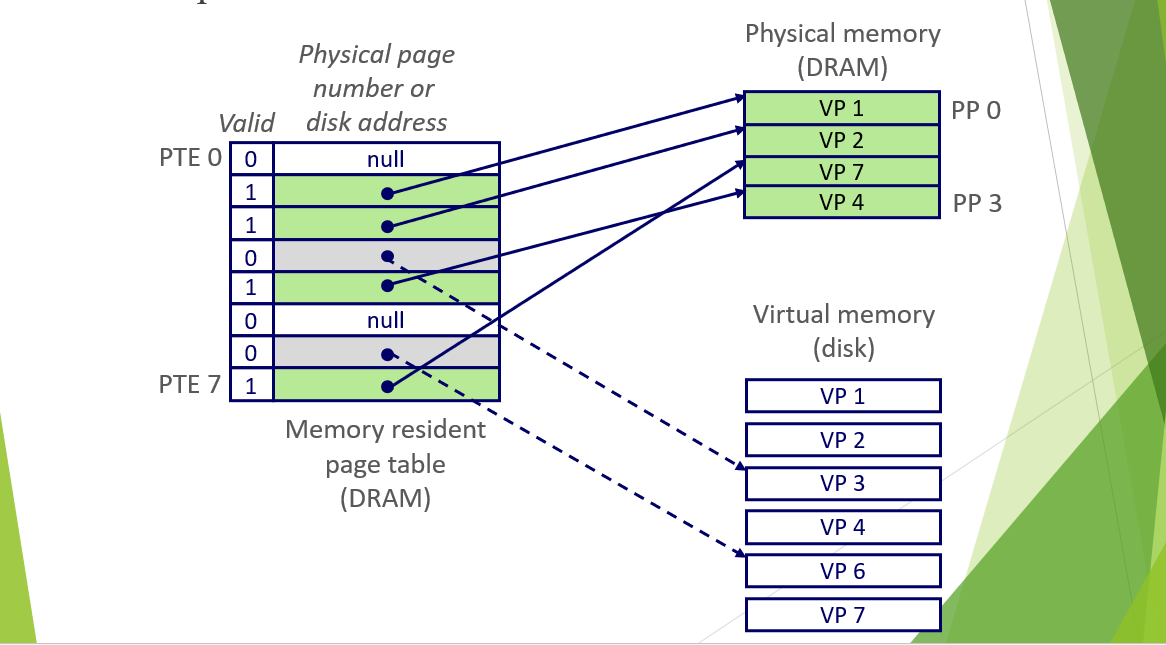
物理位置关系
Memory resident page table位于DRAM上,physical memory也在DRAM上,而Virtual Memory 在Disk上。图中第二幅图PTE上显示为null的意思是没有还没有进行分配。
当CPU中运行的程序想要使用数据时,通过把虚拟地址提供给MMU,MMU查看page table。如果当前数据所在的page是cached的,就到对一个的Physical Memory的物理地址上去取数据,即Page Hit了。否则,就需要到Disk上的Virtual上去寻找目标page。但是现在Physical Memory已经满了(图中),那就需要选出一个victim page,被我们需要的page替换掉(在替换的时候把被替换掉的数据写入Disk,即采用的是Write-back的思路),同时更改page table上的信息,这被称为 page fault。接着重复执行一次刚才的指令操作,这一次的数据已经是Cached的了,因此可以把数据给CPU。
按照这种机制,physical memory中的数据被反复替换代价是非常高的。但是呢,由于神奇的locality,程倾向于使用固定的内存。这部分内存被称为working set。如果working set的大小比main memory 小,那就不会产生任何问题,不会发生替换。但是如果working set太大,或是CPU同时运行很多程序,拿确实会连续fault,非常影响效率(少年,换大内存吧~ )。
VM as a tool for memory management
每个程序都有自己的Virtual address space,在程序看来自己被分配到的内存都是连续的。
而每一块内存(Disk 上的)都可以分配给任意的virtual pages因此两个不同的Virtual pages可以对应同一个Physical Address Space,方便程序交换数据。
Address translation
那么,CPU使用的虚拟地址和实际物理地址在MMU中是如何被转换成实际地址的呢?
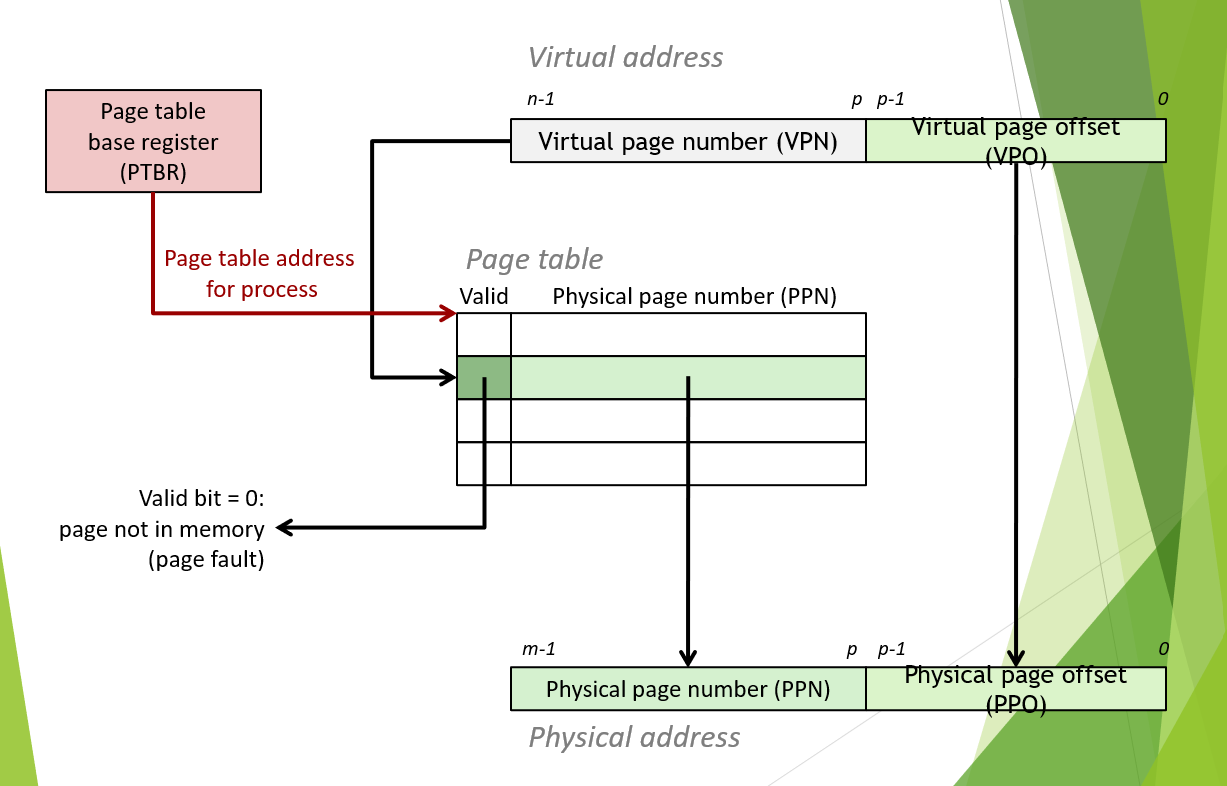
地址的转换
如图所示,virtual address由两部分组成,virtual page number(VPN)和virtual page offset(VPO)。VPN是page table中对应的编号,VPO是在virtual page中,目标地址的偏移量。physical address同样由两部分组成,Physical page number(VPP)和physical page offset(PPO,与VPO相等)。而page table,就是查询VPN对应的PPN的表单。
Page table entry(PTE):页表条目,page table中的内容。entry有条目的意思。上图中page table的每一行都叫做一个PTE。
Page Hit:
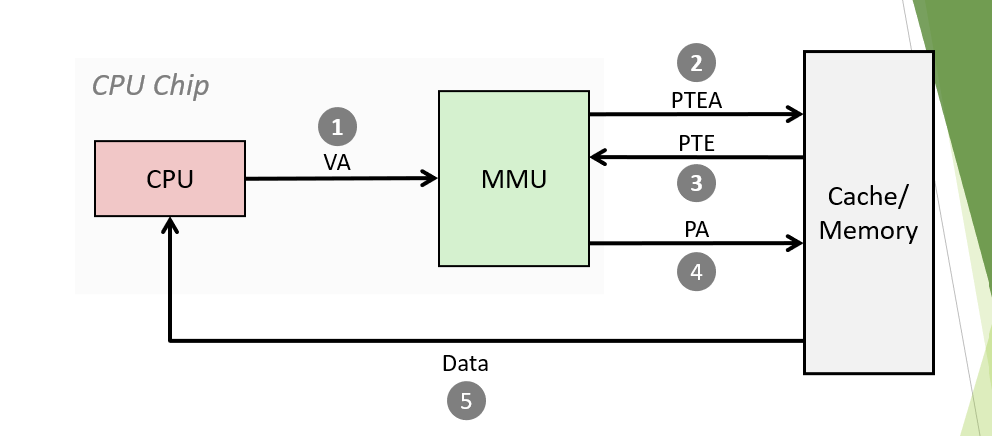
Page Hit
1、CPU给MMU提供virtual address。
2-3、MMU去page table中得到对那个的条目(包含VPN->PPN的转换信息),计算出physical address。
4-5、使用physical address去内存/缓存中得到数据,并返回给CPU。
从这里我们可以看出,前面学的Cache缓存机制,缓存的是physical address。
Page fault:

Page Fault
1-3步骤相同。但是得到PTE后发现Valid位为0(不可用),则要执行page fault handler。
计算机会寻找victim page进行替换,把需要的page更新到page table中,然后返回需要的数据。
TLB—translation lookaside buffer:
TLB是一种缓存机制,是MMU上的一个硬件。TLB缓存了page table的一部分。这样在大多数情况下,MMU就不需要组page table中实际查询,而是可以直接查询TLB,得到需要的PTE信息(TLB hit)。
同缓存一样,当TLB中没有目标信息时(TLB miss),就需要去page table中查询,更新TLB后在查询。
Chapter 6: IO System
Bus architecture
总线:总线是一种计算机内的通信结构,负责在不同的部件之间传递信息。
常见的Bus system:
CPU oriented bus system architecture
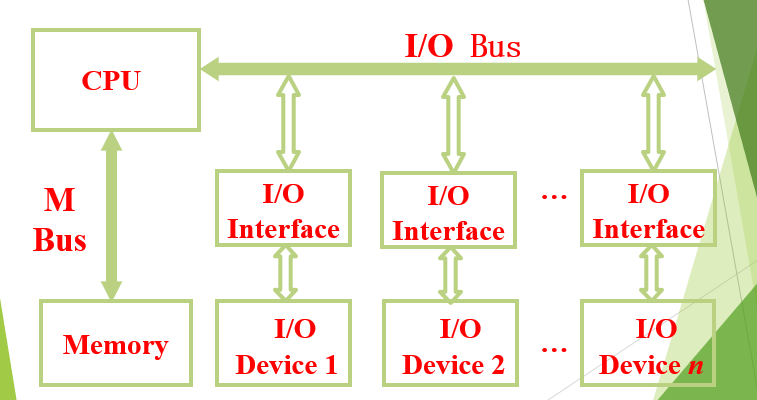
1:面向CPU的总线架构
这种架构的特点是有一个发送者和多个接收者,所有设备以CPU为核心进行操作。有点是简单方便,但是会增加CPU的负担,降低CPU的执行效率。
Single Bus Architecture
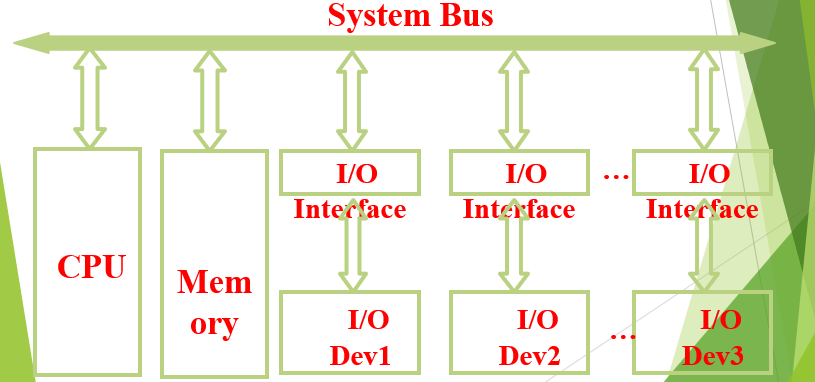
2:单总线的总线架构
这种架构中,CPU特作为连接到single Bus中的一个组件,除CPU意外的其他组件也可以公国system bus直接交流了。
Memory oriented bus architecture
以 Single Bus为基础,在CPU和Memory之间增加Memory Bus来直接传递数据。
Category of bus
计算机中有三种总线:
-
On-chip bus(片上总线):在board上,连接cache和register。
-
System bus(系统总线):在processor,memory,I/O information transforming。有三种,分别是 Data,Address,Control。
-
Communication bus:在计算机与计算机之间、计算机与外设之间传递信息。
Data bus:
- 双向数据传输:Bi-directional data transmission
- 数据总线的的位数称为数据总线宽度(data bus width)
Address bus:
- Single direction bus
- 用来指定memory或者I/O设备中储存单元的位置
地址总线的位数与储存单元的个数有关。
Control bus:
- transmit control signals
- One direction
- Reset, Clock, interrupt, bus request, memory read&write, I/O read&write……
Communication bus:
传送的速度与距离成反比。有几种类型的通信总线:
Serial 串行:
一根线,一位一位地依次传输。因此具有low cost和short range的特点。
Parallel 并行:
多根线同时传输,一般距离不超过30m,速度更快。
Bus Architecture
使用不同的设备时的集中不同的总线设计思路。
复习重点:给定计算机中的已有设备如memory,cache,高/低速外设……,设计对应的总线架构。
Uni-bus 单总线:
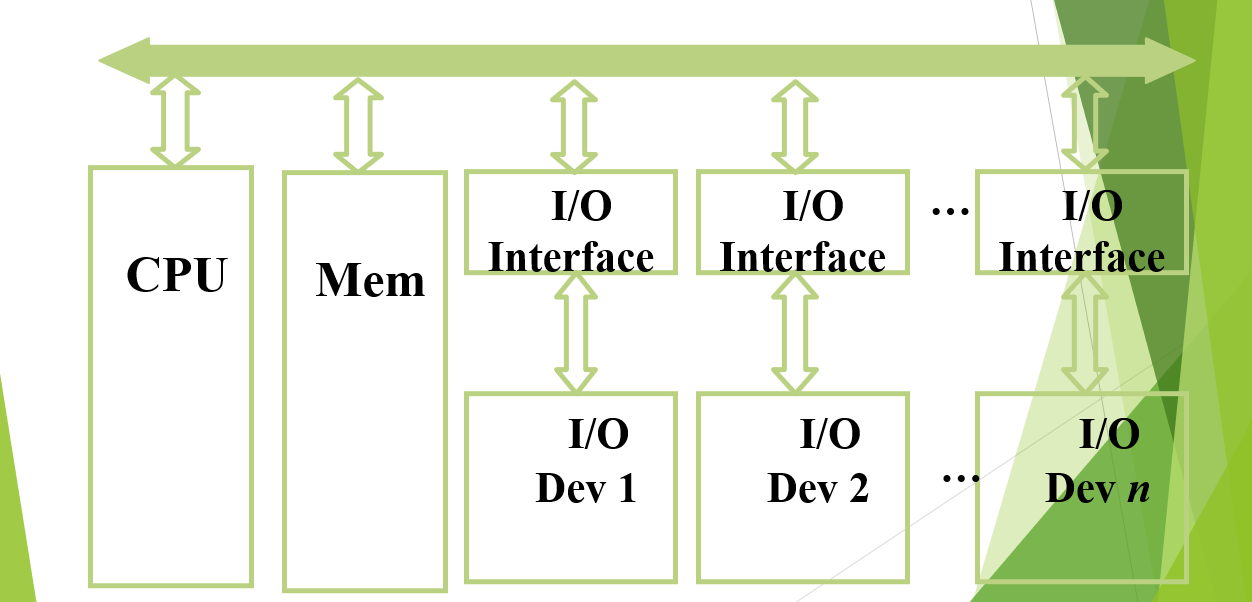
单总线架构
特点:结构简单,易于扩展,但是低速、存在瓶颈。
Multi-bus: Double bus :
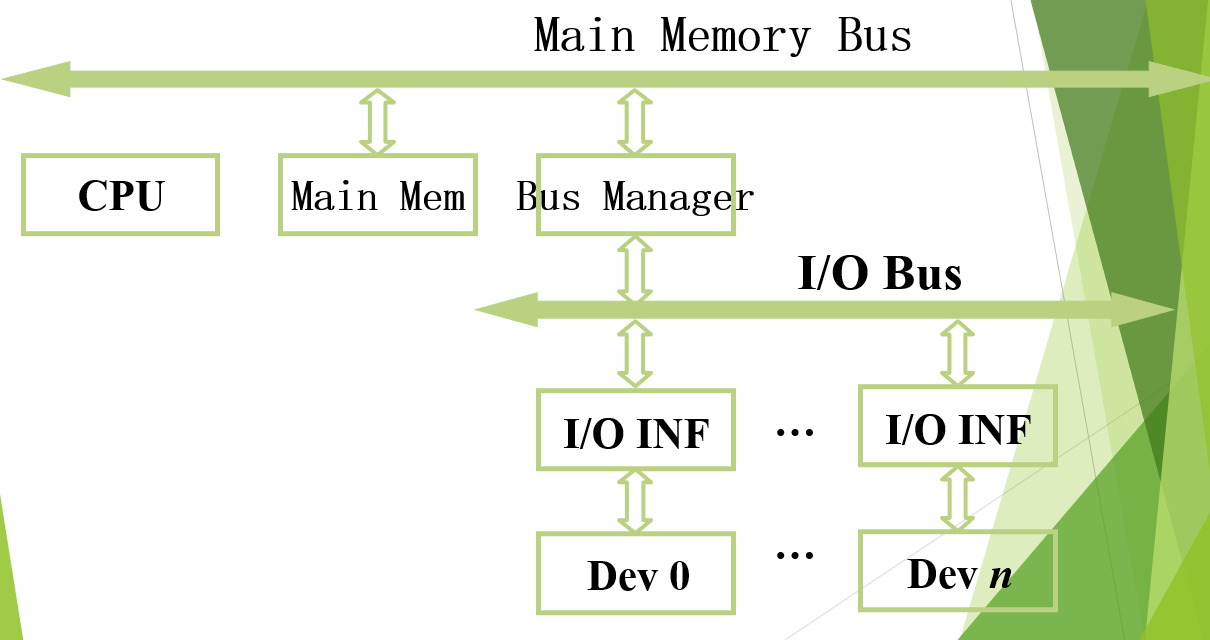
双总线架构
增加了I/O bus,将I/O设备(相对memory,CPU等来说属于低速设备)通过Bus Manager单独管理,不直接接入Main Memory Bus。
Multi-bus: Triple bus :
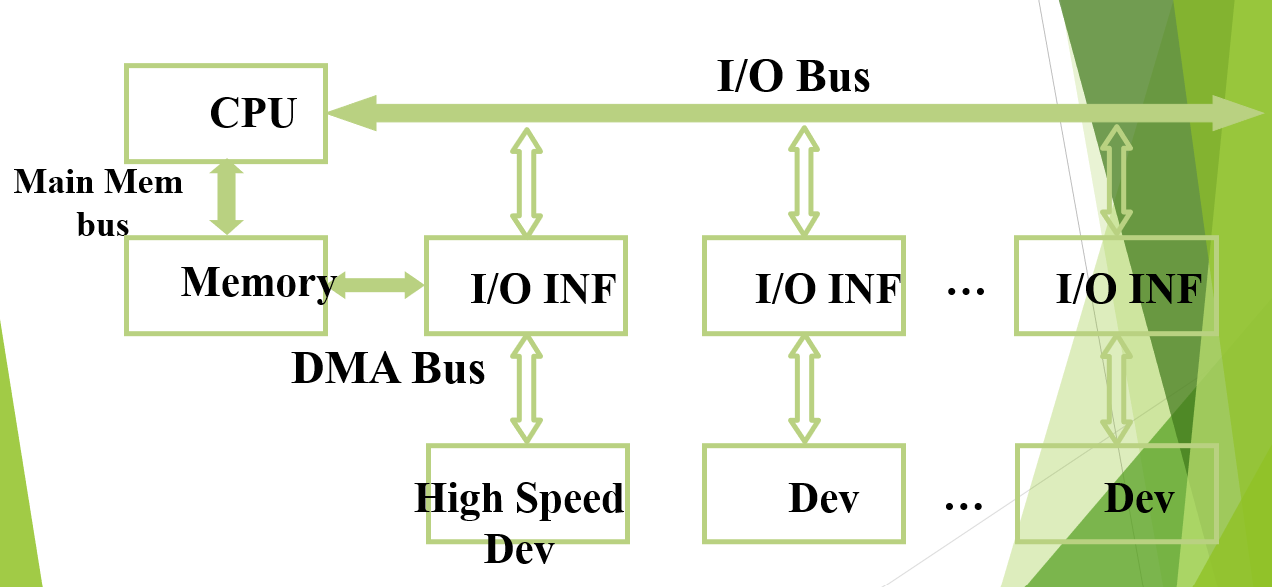
三总线架构-1
在Memory和高速I/O设备之间增设DMA bus,使得总线的分工更明确。
Main memory bus用来在CPU和Memory之间传送信息。I/O bus负责CPU和I/O设备间传递信息。DMA负责在Memory和需要频繁访问内存的I/O设备之间传送数据。
Multi-bus: Triple bus 2:
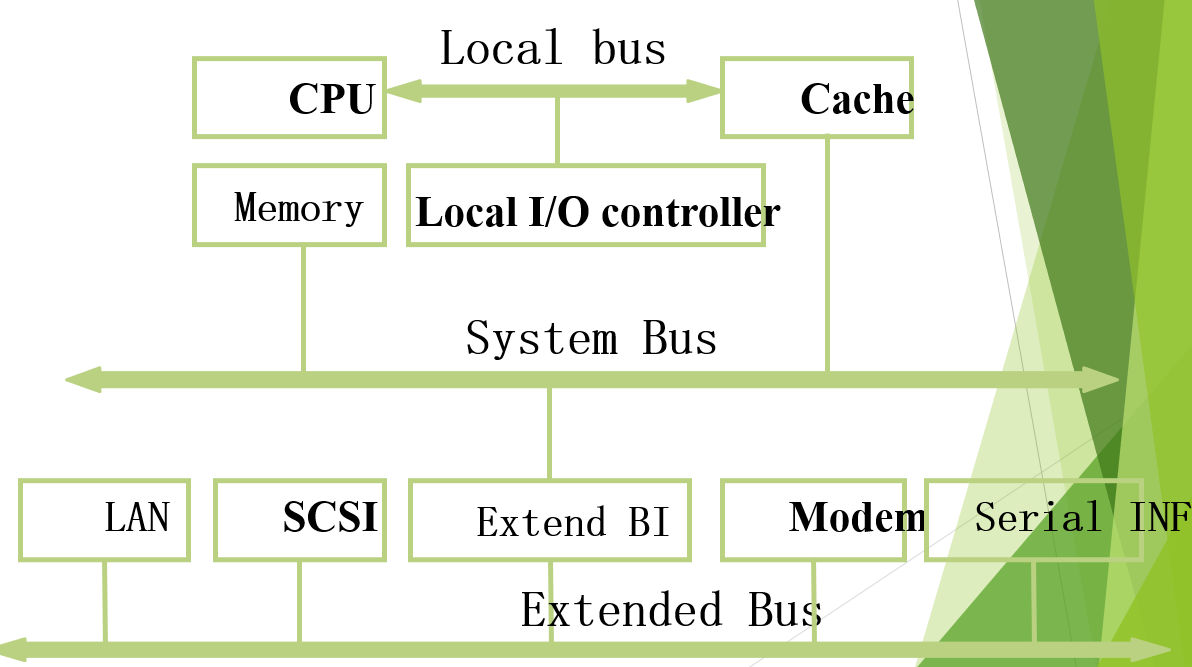
三总线架构-2
Local bus, System bus和Extended Bus的三总线结构,把Cache考虑进来。
CPU通过Local Bus与Cache和Local Cache controller联系起来。CPU没有直接接入System bus,而是通过Cache与System bus间接与Memory和Extend BI交流信息。而LAN,SCSI等外设与Extended BI以单总线的结构联系到了一起。
Multi-bus: Four bus:
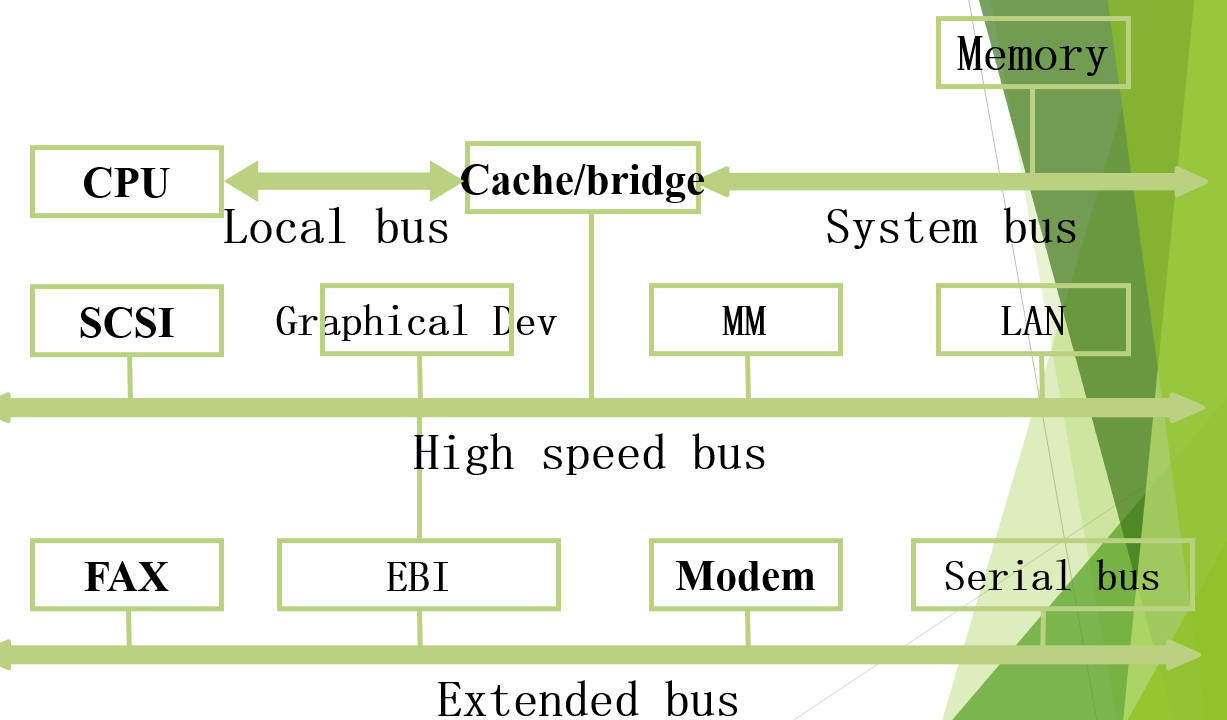
四总线架构
四总线架构。分别是Local,System,Hight speed,Extended bus。特点是把告诉外设分离出来直接通过 High speed bus来连接,其他的外设仍然通过extended bus连接。
Bus Control
计算机工作时需要同时连接很多I/O设备,但是总线只有一条。如何控制不同I/O设备的使用总线是一个重要问题。
Chain Query Model:
所有设备使用一根request bus和system bus。CPU按照顺序查询I/O设备是否有bus request 信号。有的话就处理该设备的信息。然后重新开始遍历。
这样做虽然易于连接和扩展,但是对错误过于铭敏感,没有优先级。如果一个设备故障导致不停的发出bus request 信号,则后面的设备都无法工作了。
Counter Query Model:
仍然使用同一根线,但是Bus Control Unit内保存一个计数器。通过查看当前计数器指向的设备有没有发出信号。有的话就处理。处理结束或是没有发出信号的话计数器+1。
但是仍然对错误比较敏感。同时增加了设备的地址和,控制变得更复杂了。
Independent Query:
所有设备单独通过Request Bus与 Bus Control Unit连接。而在UCU内部有一个queue,按照优先级处理设备的request信号。
这种方式有 Fast response, flexible priority control, complex logical, massive control buses的特点。
I/O technology
I/O Model
I/O model是介于属于system bus 和 peripherals(外设)之间的一个部件,负责管理和控制I/O与CPU的交互。一个I/O model负责控制一个或多个peripherals,它会执行很多逻辑控制的操作。
外设不会直接连接到总线上,处于以下几个原因:外设种类的多样性、数据的传送效率,数据的格式问题。
因此,I/O model负责通过系统总线与CPU和Memory交互;还负责通过特定线路与一个或多个设备交互。
External devices
外设外设一般被称为external device,但是跟I/O连接的外设经常被称为peripheral device 或者直接称为.peripheral。
外设需要具有三个性质。即Human readable,适合同计算机使用者沟通;Machine readable,适合同计算机交流;Communication readable,适合同远程设备交流。
Functions and Requirements
- Control and timing
- 处理器询问I/O model设备的状态
- I/O model返回设备的状态
- 如果状态 operational and ready to transmit,则处理器通过I/O Model 请求传输数据。
- I/O model 获得设备传递过来的信息
- 数据通过I/O Model 传递给处理器
- Processor communication
- Command decoding:将CPU通过控制总线传递过来的信号译码为指令。
- Data:与CPU通过数据总线互相传送数据
- Device communication
- Statue reporting: 由于外设的处理速度很慢,因此CPU需要通过I/O model来及时获得设备的状态(busy or ready)或是报告设备的错误信息
- Address recognition: I/O model需要识别由它所控制的设备的唯一地址
-
Data buffering
- Error detection
外设传递过来的信息中可能或有一些错误,I/O model会对数据做一定的检查
I/O technology
Programmed I/O
程序查询式:数据在处理器和I/O model之间传送。处理器对设备发出命令,如感知设备状态,发送读/写命令、传送数据等。将命令传递给I/O model后,CPU持需要连续地询问I/O model命令是否完成,不会执行其他指令,直到该命令完成。
四种I/O操作
- Control: 控制外设执行操作(如让相机拍照等)
- Test: 检查设备是否空闲或损坏
- Read: 让 I/O model从设备中读取一些信息(键盘)
- Write: 让 I/O model将一些数据传送到设备中(U盘)
Interrupt-driven I/O
中断式:处理器发送完命令后,接着取执行其他工作。直到I/O model完成操作后给处理其发送中断命令。
在 programmed I/O 模式中,处理器反复询问命令的执行状态极大的降低了使用下效率。因此可以选择让CPU在次区间去做一些其他的事情。当命令完成后,I/O model 发出指令打断CPU,然后CPU回到执行数据传送,继续刚才的工作。
在这个过程中,最重要的就是中断的操作。
中断
中断指的是由软件或者硬件发出的信号,表示有需要立即注意的事项。具有高优先级的中断会打断处理器正在处理的事项。处理器会停止当前活动,保存当前的状态然后执行Interrupt Handler 中断处理程序。在中断处理结束后,处理器会恢复中断前的状态,然后继续指向之前的工作。
Interrupt Handler也叫做Interrupt service routine(ISR),是位于微处理器、硬件、操作系统或设备驱动中的一个call-back函数。
interrupt processing
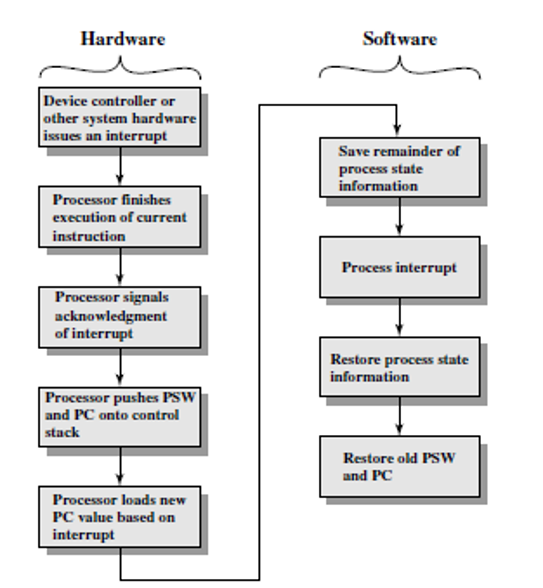
Interrupt processing(高糊)
具体的中断执行流程是一个软硬件结合的过程:
-
设备向处理器发出中断信号
-
处理器接触当前指令的执行
-
处理器检查是否有中断信号。确认后中断信号后,向设备发出”Acknowledge”信号,设备收到信号后停止发出中断信号。处理器接下来开始处理中断
-
处理器需要保存回复当前状态所需要的信息,包括叫做”program status word(PSW)”的寄存器,吓一跳指令的地址。这些都会被压入栈中。
-
处理器把PC值更新为处理该中断的程序的起始地址,开始响应中断。
-
中断处理程序接下来处理中断。例如检查相关的I/O设备的状态等导致中断的原因……
-
中断处理结束后,保存的寄存器的值从栈中弹出,恢复。
-
恢复PC和PSW的值,处理器继续执行中断前的任务。
由于减少了不必要的等待时间,Interrupt I/O 比 programmed I/O 的效率要高。但是,由于所有的数据都需要通过I/O model和处理器来传送,仍然需要很长时间。
中断可以有优先级和抢占。同时又两个优先级相同的中断信号时,处理器按照顺序执行。否则优先级较高的执行。当然,在中断的处理过程中,也可以被优先级更高的中断抢占,先执行。
Direct memory access (DMA)
DMA: I/O model和Memory可以直接进行数据交换,不需要处理器来参与。
前两种I/OF方式的数据传输速度被处理器的处理速度限制住了,当又大量的数据需要传输时,需要更有小笼包的技术,即 DMA。
DMA涉及到system bus上的一个独立模块。当DMA使用总线的时候,COU就没有办法使用总线了,因此DMA在CPU不适用总线的时候执行或者将CPU挂起。
当处理器需要读/写数据块时:
- 向DMA module发出一个命令,同时发送下列信息给DMA: read/write处理器和DMA之间的控制线路;目标I/O设备的地址;开始读/写的位置;需要读/写的大小。
- 之后处理器继续执行其他工作,DMA开始将数据模块在I/O设备和memory之间传送。不经过处理器
- 数据传送结束后,DMA向处理器发出一个中断,提醒处理器数据传送完成了。这个中断不需要处理。
这样,处理器只在开始和结束的时候参与,之后就不需要处理了。
Chapter 7: CU
一条指令的执行由被称为Instruction Cycles(指令周期)的Fetch、Decode、Execute、Visit memory、Write Back等操作构成。而每个Cycle又由一系列更底层的微小操作构成。一个单独的微操作一般包括寄存器之间的数据传输、寄存器和外部总线之间的数据传输、或者是ALU的操作。
处理器的Control Unit主要由时序和控制两大功能,即根据程序以适当的顺序执行一系列微操作、同时产生一系列微操作需要的控制信号。控制信号即逻辑门的开闭,导致数据的传输或是ALU的功能执行。
这一章主要讲述的就是指令的每一个环节硬件上CPU都做了写什么。而分解操作又两种不同的架构方式。一种是硬布线、即硬件层面的微操作来实现。另一种是通过调用更底层微指令控制来完成指令操作。
Control Unit Operation
Micro-operation 微操作
一种实施CU的方式就是hardwired implementation(硬布线),它将当前的机器指令转化为一系列逻辑门上控制信号。对处理器来说,Micro-operations是用来实现复杂机器指令的底层指令细节。
一个指令周期可以由一些列操作组成。具体的划分由很多种,本章将使用 fetch、indirect、execute,interrupt的划分方式。在所有的划分方式中。fetch和execute总是存在的。之前学过的Visit Memory、Write back……也是一种划分方式。
Fetch 取址
Memory address register(MAR): 与系统总线的地址线连接在一起,指定了read/write操作中的地址。
Memory buffer register(MBR): 与地址线连接在一起,包换预备要储存到memory中的数据或是最近一次读出来的数据。
Program counter(PC): 指向下一条指令的地址
Instruction register: 储存最近一条指令fetch情况。
- 在fetch的开始阶段,将要执行的指令地址还储存在PC中。因此第一步就要1’将PC中的地址移动到MAR(唯一与地址总线连接的寄存器)中。
- MAR将地址提供给地址总线,CU在控制总线上发出read信号,2’目标数据从数据总线传送到MBR上。
- 根据指令的长度3’更新PC的值;同时4’将MBR中的指令移动到IR中。MBR被腾出用于后续的indirect操作。
因此,fetch操作包含三步、四个微操作(数据的移动)。由于部分微操作不冲突,可以在同时进行节省时间。例如3’也可以和2’放到一步里。
问:如何去group微操作?
答:
- 正确的顺序,不能颠倒逻辑的先后顺序 proper sequence of events must be followed
- 不会发生冲突 Conflicts must be avoid
Indirect 简址
取址结束后,就需要去去操作数。但是操作数由直接寻址的,也有简介寻址的。因此需要在indirect在一部将间接地址转化为直接地址。具体实施步骤:
- MAR <- (IR(Address))
- MBR <- Memory
- IR(Address) <- (MBR(Address))
Execute 执行
执行的情况最多样。与其他三个阶段相对固定化,变化小的微操作不同,根据命令的不同,Execute的情况也不同。因此我们只能以ADD R1, X(把X的值加到R1上)为例来说明execute的过程。
首先,把IR中的地址导入MAR中,然后去对应的地址读取数据到MBR,最后使用ALU将数据加起来。
- MAR <- (IR (address))
- MBR <- Memory
- R1 <- (R1)+(MBR)
Interrupt 中断
首先,PC的值被储存到MBR中,之后被储存起来用于后续的恢复;接着MAR被导入了PC内容的储存地址,同时PC更新成中断执行的命令;最后,MBR中的数据被储存到Memory中。
- MBR <- (PC)
- MAR <- Save_Address
PC <- Routine_Address - Memory <- (MBR)
CU如何控制时序呢?我们设想现在有一个2bits的寄存器,叫做 instruction cycle code(ICC), 则可以用ICC来记录和表示现在处于哪一个阶段(二进制0-3,4中状态。)
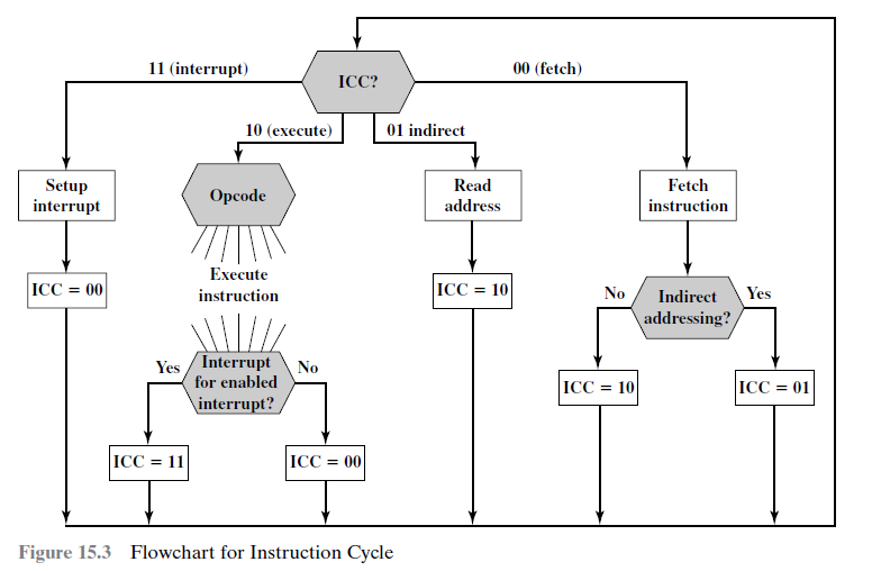
Flowchart for Instruction Cycle
Control of the processor
CU的描述:
- 定义了处理器的基本要素
- 描述处理器执行的微操作
- 决定处理器为了使得微操作正确实行所需要的功能
Control Tasks:
Sequencing 时序: 使处理器根据所所执行的程序按照正确顺序逐步执行微操作
Executing 执行: 控制每一条微指令正确执行
Input and Output:
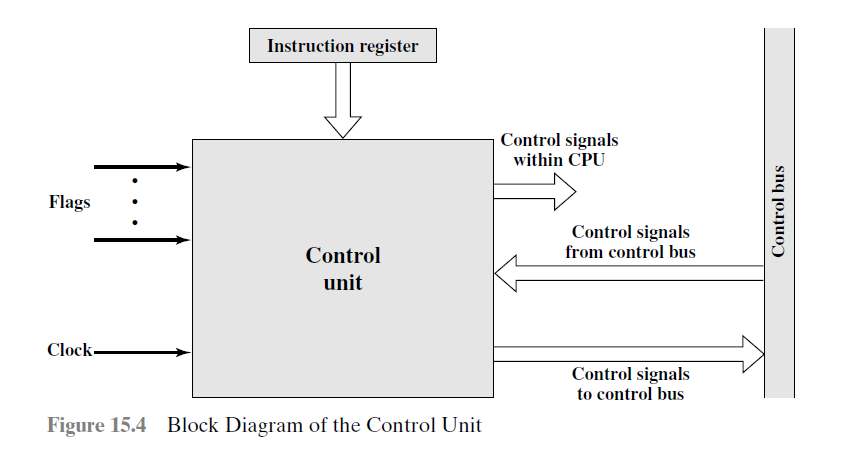
Control Signals
输入:
Clock: 处理器的始终周期,用来Keep Time,CU因此得以使得每个微操作在一个始终周期内运行而不发生冲突。
Instruction register: 内部储存的opcode和addressing mode被用来判断当前周期应该执行什么操作。
Flags: 用来判断当前的处理器处理器和上轮ALU计算结果的状态
Control signals from control bus: 给CU提供信号
输出:
Control signals within CPU: 有两种,移动寄存器中的数据或激发ALU特定的计算功能
Control signals to control bus: 给Memory和I/O设备的控制信号
Micro-programmed Control
另一种CU的实现方式是通过micro-programmed(微程序)控制。CU将每一条机器指令转换为微程序,由微程序具体控制逻辑门等硬件。微程序是一系列伪指令的组合。微程序CU的逻辑电路相对简单,只需要对微指令进行排序,让微指令来产生控制信号。微指令产生的控制信号同样用来进行寄存器之间的数据传输和ALU操作。
Basic Concept 基本理念:CU需要根据指令对微操作进行排序、解释操作码、并对ALU的状态做出判断。
Micro-Instructions:
一个信号可以表示on 和 off,对各信号可以用一个多位的二进制数表示,这个二进制数就叫做Control Word,它的每一位都代表一条控制线。这样,每个微操作都可以用Control Word中的0和1来表示。
微指令的经典格式
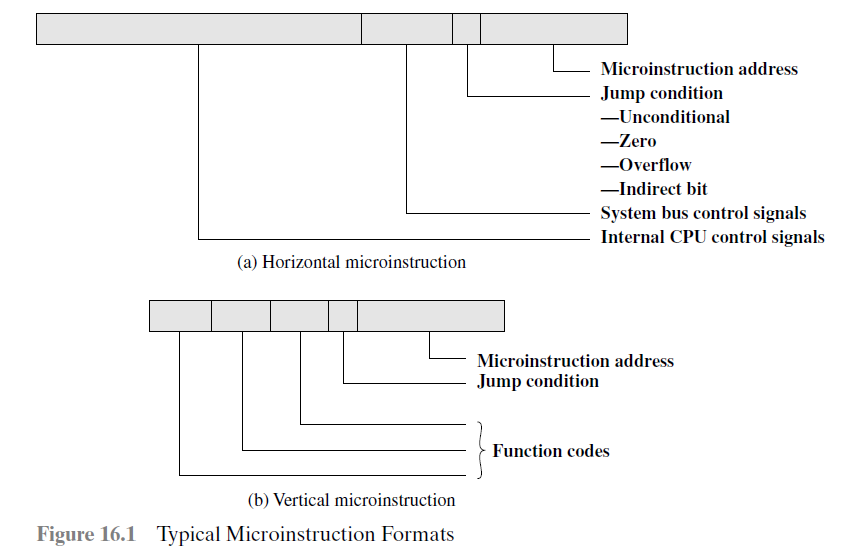
Typical Microinstruction Format
两种不同的微指令格式:
水平型:微程序短,执行速度快,但是指令较长、编写程序比较麻烦
垂直型:类似机器指令,简单、规整。
微指令的解释
执行Control Word中所有表示为1的指令。如果某一位是0,则执行下一位所代表的微指令。如果为1,则把指令的地址传递给address field(执行)。
Micro programmed Control Unit
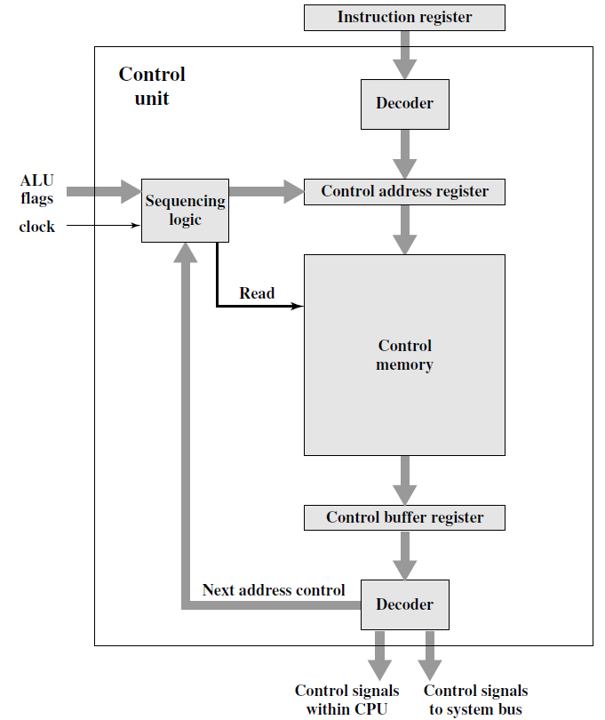
Micro programmed Control Unit
所有的微指令都储存在Control Memory中。Control address register中保存了下一条要读取的指令的地址。当Control memory接收到read指令时,对应的微指令会传送到Control buffer register中。在Control buffer中decode,产生控制信号和下一条微指令的地址。Sequencing logic根据ALU的状态和得到的下一条微指令地址给Control address register提供新的地址。
对于微指令控制器来说,读一条微指令的过程就等同于执行的过程,读完即执行完。
Sequencing and Executing:
微程序控制器的两大功能是Sequencing时序和Executing执行。
时序:从Control Memory中得到下一条微指令。
执行:产生执行微指令所需要的信号。
在设计微指令的时序时,有两个重要的地方需要考虑,一个是微指令的大小(size),另一个是禅城微指令地址的时间。在执行微程序时,下一条要执行的微指令的地址有几种可能来源:由IR决定/下一个顺序地址/分支。
微程序控制器也有cycle,但是相对简单,只包括Fetch和Execute两部分。